Coursera
Tweet Emotion Recognition: Natural Language Processing with TensorFlow
Dataset: Tweet Emotion Dataset
This is a starter notebook for the guided project Tweet Emotion Recognition with TensorFlow
A complete version of this notebook is available in the course resources
Task 1: Introduction
Task 2: Setup and Imports
- Installing Hugging Face’s nlp package
- Importing libraries
!pip install nlp
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting nlp
Downloading nlp-0.4.0-py3-none-any.whl (1.7 MB)
[K |████████████████████████████████| 1.7 MB 13.3 MB/s
[?25hRequirement already satisfied: pyarrow>=0.16.0 in /usr/local/lib/python3.7/dist-packages (from nlp) (6.0.1)
Collecting xxhash
Downloading xxhash-3.0.0-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (212 kB)
[K |████████████████████████████████| 212 kB 37.4 MB/s
[?25hRequirement already satisfied: filelock in /usr/local/lib/python3.7/dist-packages (from nlp) (3.7.1)
Requirement already satisfied: dill in /usr/local/lib/python3.7/dist-packages (from nlp) (0.3.5.1)
Requirement already satisfied: requests>=2.19.0 in /usr/local/lib/python3.7/dist-packages (from nlp) (2.23.0)
Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.7/dist-packages (from nlp) (4.64.0)
Requirement already satisfied: pandas in /usr/local/lib/python3.7/dist-packages (from nlp) (1.3.5)
Requirement already satisfied: numpy in /usr/local/lib/python3.7/dist-packages (from nlp) (1.21.6)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests>=2.19.0->nlp) (3.0.4)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests>=2.19.0->nlp) (2.10)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests>=2.19.0->nlp) (1.24.3)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests>=2.19.0->nlp) (2022.6.15)
Requirement already satisfied: pytz>=2017.3 in /usr/local/lib/python3.7/dist-packages (from pandas->nlp) (2022.1)
Requirement already satisfied: python-dateutil>=2.7.3 in /usr/local/lib/python3.7/dist-packages (from pandas->nlp) (2.8.2)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/dist-packages (from python-dateutil>=2.7.3->pandas->nlp) (1.15.0)
Installing collected packages: xxhash, nlp
Successfully installed nlp-0.4.0 xxhash-3.0.0
%matplotlib inline
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import nlp
import random
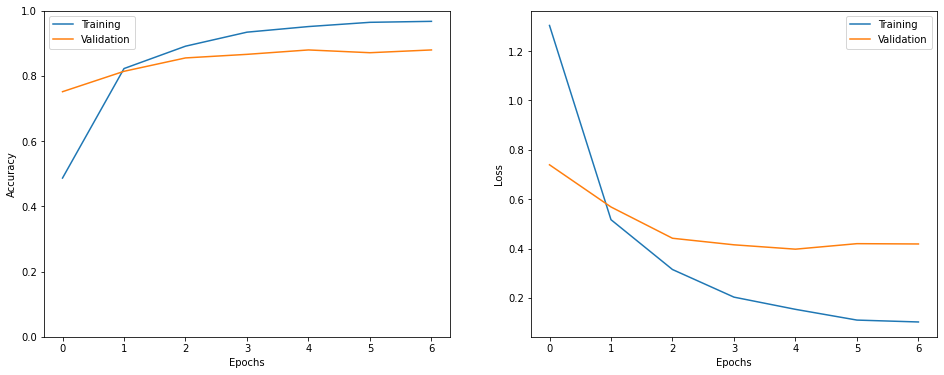
def show_history(h):
epochs_trained = len(h.history['loss'])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
plt.plot(range(0, epochs_trained), h.history.get('accuracy'), label='Training')
plt.plot(range(0, epochs_trained), h.history.get('val_accuracy'), label='Validation')
plt.ylim([0., 1.])
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(range(0, epochs_trained), h.history.get('loss'), label='Training')
plt.plot(range(0, epochs_trained), h.history.get('val_loss'), label='Validation')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
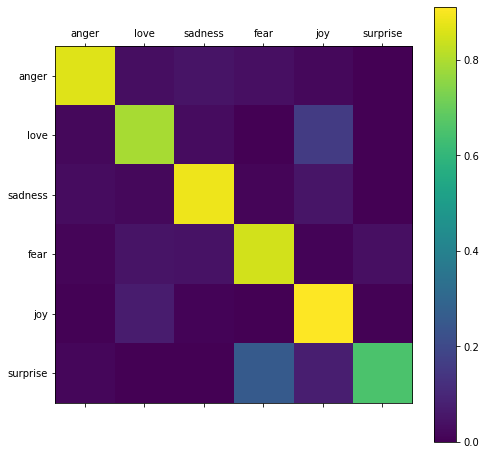
def show_confusion_matrix(y_true, y_pred, classes):
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_true, y_pred, normalize='true')
plt.figure(figsize=(8, 8))
sp = plt.subplot(1, 1, 1)
ctx = sp.matshow(cm)
plt.xticks(list(range(0, 6)), labels=classes)
plt.yticks(list(range(0, 6)), labels=classes)
plt.colorbar(ctx)
plt.show()
print('Using TensorFlow version', tf.__version__)
Using TensorFlow version 2.8.2
Task 3: Importing Data
- Importing the Tweet Emotion dataset
- Creating train, validation and test sets
- Extracting tweets and labels from the examples
dataset = nlp.load_dataset('emotion')
Downloading: 0%| | 0.00/3.41k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/6.01k [00:00<?, ?B/s]
Using custom data configuration default
Downloading and preparing dataset emotion/default (download: 1.97 MiB, generated: 2.09 MiB, post-processed: Unknown sizetotal: 4.06 MiB) to /root/.cache/huggingface/datasets/emotion/default/0.0.0/84e07cd366f4451464584cdbd4958f512bcaddb1e921341e07298ce8a9ce42f4...
Downloading: 0%| | 0.00/1.66M [00:00<?, ?B/s]
Downloading: 0%| | 0.00/204k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/207k [00:00<?, ?B/s]
0 examples [00:00, ? examples/s]
0 examples [00:00, ? examples/s]
0 examples [00:00, ? examples/s]
Dataset emotion downloaded and prepared to /root/.cache/huggingface/datasets/emotion/default/0.0.0/84e07cd366f4451464584cdbd4958f512bcaddb1e921341e07298ce8a9ce42f4. Subsequent calls will reuse this data.
dataset
{'test': Dataset(features: {'text': Value(dtype='string', id=None), 'label': Value(dtype='string', id=None)}, num_rows: 2000),
'train': Dataset(features: {'text': Value(dtype='string', id=None), 'label': Value(dtype='string', id=None)}, num_rows: 16000),
'validation': Dataset(features: {'text': Value(dtype='string', id=None), 'label': Value(dtype='string', id=None)}, num_rows: 2000)}
train = dataset['train']
test = dataset['test']
val = dataset['validation']
def get_tweet(data):
tweets = [x['text'] for x in data]
labels = [x['label'] for x in data]
return tweets, labels
tweets, labels = get_tweet(train)
tweets[0], labels[0]
('i didnt feel humiliated', 'sadness')
Task 4: Tokenizer
- Tokenizing the tweets
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer(num_words = 10000, oov_token = '<UNK>')
tokenizer.fit_on_texts(tweets)
tokenizer.texts_to_sequences([tweets[0]])
[[2, 139, 3, 679]]
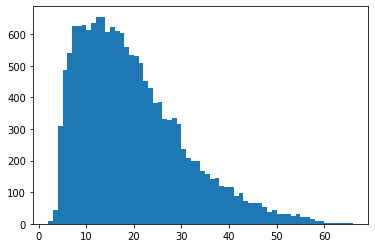
Task 5: Padding and Truncating Sequences
- Checking length of the tweets
- Creating padded sequences
lengths = [len(t.split(' ')) for t in tweets]
plt.hist(lengths, bins = len(set(lengths)))
plt.show()
maxlen = 50
from tensorflow.keras.preprocessing.sequence import pad_sequences
def get_sequences(tokenizer, tweets):
sequences = tokenizer.texts_to_sequences(tweets)
padded = pad_sequences(sequences, truncating = 'post', padding = 'post', maxlen = maxlen)
return padded
padded_train_seq = get_sequences(tokenizer, tweets)
padded_train_seq[0]
array([ 2, 139, 3, 679, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32)
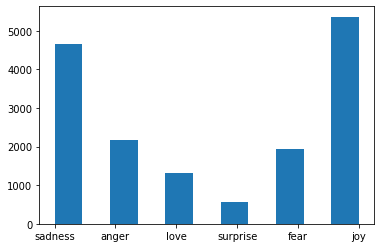
Task 6: Preparing the Labels
- Creating classes to index and index to classes dictionaries
- Converting text labels to numeric labels
classes = set(labels)
print(classes)
{'anger', 'love', 'sadness', 'fear', 'joy', 'surprise'}
plt.hist(labels, bins = 11)
plt.show()
class_to_index = dict((c, i) for i, c in enumerate(classes))
index_to_class = dict((v, k) for k, v in class_to_index.items())
class_to_index
{'anger': 0, 'fear': 3, 'joy': 4, 'love': 1, 'sadness': 2, 'surprise': 5}
index_to_class
{0: 'anger', 1: 'love', 2: 'sadness', 3: 'fear', 4: 'joy', 5: 'surprise'}
name_to_ids = lambda labels: np.array([class_to_index.get(x) for x in labels])
train_labels = name_to_ids(labels)
print(train_labels[0])
2
Task 7: Creating the Model
- Creating the model
- Compiling the model
model = tf.keras.models.Sequential([
tf.keras.layers.Embedding(10000, 16, input_length = maxlen),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(20, return_sequences = True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(20)),
tf.keras.layers.Dense(6, activation = 'softmax')
])
model.compile(
loss = 'sparse_categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy']
)
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 50, 16) 160000
bidirectional (Bidirectiona (None, 50, 40) 5920
l)
bidirectional_1 (Bidirectio (None, 40) 9760
nal)
dense (Dense) (None, 6) 246
=================================================================
Total params: 175,926
Trainable params: 175,926
Non-trainable params: 0
_________________________________________________________________
Task 8: Training the Model
- Preparing a validation set
- Training the model
val_tweets, val_labels = get_tweet(val)
val_seqs = get_sequences(tokenizer, val_tweets)
val_labels = name_to_ids(val_labels)
val_tweets[0], val_labels[0]
('im feeling quite sad and sorry for myself but ill snap out of it soon', 2)
h = model.fit(
padded_train_seq, train_labels,
validation_data = [val_seqs, val_labels],
epochs = 20,
callbacks = [
tf.keras.callbacks.EarlyStopping(monitor = 'val_accuracy', patience = 2)
]
)
Epoch 1/20
500/500 [==============================] - 17s 17ms/step - loss: 1.3037 - accuracy: 0.4867 - val_loss: 0.7393 - val_accuracy: 0.7515
Epoch 2/20
500/500 [==============================] - 7s 14ms/step - loss: 0.5169 - accuracy: 0.8224 - val_loss: 0.5684 - val_accuracy: 0.8140
Epoch 3/20
500/500 [==============================] - 7s 14ms/step - loss: 0.3150 - accuracy: 0.8910 - val_loss: 0.4416 - val_accuracy: 0.8550
Epoch 4/20
500/500 [==============================] - 8s 15ms/step - loss: 0.2031 - accuracy: 0.9340 - val_loss: 0.4151 - val_accuracy: 0.8660
Epoch 5/20
500/500 [==============================] - 7s 14ms/step - loss: 0.1537 - accuracy: 0.9512 - val_loss: 0.3974 - val_accuracy: 0.8795
Epoch 6/20
500/500 [==============================] - 7s 14ms/step - loss: 0.1102 - accuracy: 0.9642 - val_loss: 0.4198 - val_accuracy: 0.8710
Epoch 7/20
500/500 [==============================] - 7s 14ms/step - loss: 0.1025 - accuracy: 0.9672 - val_loss: 0.4185 - val_accuracy: 0.8795
Task 9: Evaluating the Model
- Visualizing training history
- Prepraring a test set
- A look at individual predictions on the test set
- A look at all predictions on the test set
show_history(h)
test_tweets, test_labels = get_tweet(test)
test_seqs = get_sequences(tokenizer, test_tweets)
test_labels = name_to_ids(test_labels)
_ = model.evaluate(test_seqs, test_labels)
63/63 [==============================] - 1s 11ms/step - loss: 0.4226 - accuracy: 0.8725
i = random.randint(0, len(test_labels) - 1)
print('Sentence:', test_tweets[i])
print('Emotion:', index_to_class[test_labels[i]])
p = model.predict(np.expand_dims(test_seqs[i], axis = 0))[0]
pred_class = index_to_class[np.argmax(p).astype('uint8')]
print('Predicted emotion:', pred_class)
Sentence: i feel i have to give credit to jen mitchell for her gorgeous card a href http www
Emotion: joy
Predicted emotion: joy
preds = np.argmax(model.predict(test_seqs), axis = -1)
show_confusion_matrix(test_labels, preds, list(classes))