Coursera
Week 4: Multi-class Classification
Welcome to this assignment! In this exercise, you will get a chance to work on a multi-class classification problem. You will be using the Sign Language MNIST dataset, which contains 28x28 images of hands depicting the 26 letters of the english alphabet.
You will need to pre-process the data so that it can be fed into your convolutional neural network to correctly classify each image as the letter it represents.
Let’s get started!
NOTE: To prevent errors from the autograder, pleave avoid editing or deleting non-graded cells in this notebook . Please only put your solutions in between the ### START CODE HERE and ### END CODE HERE code comments, and refrain from adding any new cells.
# grader-required-cell
import csv
import string
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import ImageDataGenerator, array_to_img
Download the training and test sets (the test set will actually be used as a validation set):
# sign_mnist_train.csv
!gdown --id 1z0DkA9BytlLxO1C0BAWzknLyQmZAp0HR
# sign_mnist_test.csv
!gdown --id 1z1BIj4qmri59GWBG4ivMNFtpZ4AXIbzg
/usr/local/lib/python3.10/dist-packages/gdown/cli.py:121: FutureWarning: Option `--id` was deprecated in version 4.3.1 and will be removed in 5.0. You don't need to pass it anymore to use a file ID.
warnings.warn(
Downloading...
From: https://drive.google.com/uc?id=1z0DkA9BytlLxO1C0BAWzknLyQmZAp0HR
To: /content/sign_mnist_train.csv
100% 83.3M/83.3M [00:00<00:00, 88.1MB/s]
/usr/local/lib/python3.10/dist-packages/gdown/cli.py:121: FutureWarning: Option `--id` was deprecated in version 4.3.1 and will be removed in 5.0. You don't need to pass it anymore to use a file ID.
warnings.warn(
Downloading...
From: https://drive.google.com/uc?id=1z1BIj4qmri59GWBG4ivMNFtpZ4AXIbzg
To: /content/sign_mnist_test.csv
100% 21.8M/21.8M [00:00<00:00, 60.1MB/s]
Define some globals with the path to both files you just downloaded:
# grader-required-cell
TRAINING_FILE = './sign_mnist_train.csv'
VALIDATION_FILE = './sign_mnist_test.csv'
Unlike previous assignments, you will not have the actual images provided, instead you will have the data serialized as csv files.
Take a look at how the data looks like within the csv file:
# grader-required-cell
with open(TRAINING_FILE) as training_file:
line = training_file.readline()
print(f"First line (header) looks like this:\n{line}")
line = training_file.readline()
print(f"Each subsequent line (data points) look like this:\n{line}")
First line (header) looks like this:
label,pixel1,pixel2,pixel3,pixel4,pixel5,pixel6,pixel7,pixel8,pixel9,pixel10,pixel11,pixel12,pixel13,pixel14,pixel15,pixel16,pixel17,pixel18,pixel19,pixel20,pixel21,pixel22,pixel23,pixel24,pixel25,pixel26,pixel27,pixel28,pixel29,pixel30,pixel31,pixel32,pixel33,pixel34,pixel35,pixel36,pixel37,pixel38,pixel39,pixel40,pixel41,pixel42,pixel43,pixel44,pixel45,pixel46,pixel47,pixel48,pixel49,pixel50,pixel51,pixel52,pixel53,pixel54,pixel55,pixel56,pixel57,pixel58,pixel59,pixel60,pixel61,pixel62,pixel63,pixel64,pixel65,pixel66,pixel67,pixel68,pixel69,pixel70,pixel71,pixel72,pixel73,pixel74,pixel75,pixel76,pixel77,pixel78,pixel79,pixel80,pixel81,pixel82,pixel83,pixel84,pixel85,pixel86,pixel87,pixel88,pixel89,pixel90,pixel91,pixel92,pixel93,pixel94,pixel95,pixel96,pixel97,pixel98,pixel99,pixel100,pixel101,pixel102,pixel103,pixel104,pixel105,pixel106,pixel107,pixel108,pixel109,pixel110,pixel111,pixel112,pixel113,pixel114,pixel115,pixel116,pixel117,pixel118,pixel119,pixel120,pixel121,pixel122,pixel123,pixel124,pixel125,pixel126,pixel127,pixel128,pixel129,pixel130,pixel131,pixel132,pixel133,pixel134,pixel135,pixel136,pixel137,pixel138,pixel139,pixel140,pixel141,pixel142,pixel143,pixel144,pixel145,pixel146,pixel147,pixel148,pixel149,pixel150,pixel151,pixel152,pixel153,pixel154,pixel155,pixel156,pixel157,pixel158,pixel159,pixel160,pixel161,pixel162,pixel163,pixel164,pixel165,pixel166,pixel167,pixel168,pixel169,pixel170,pixel171,pixel172,pixel173,pixel174,pixel175,pixel176,pixel177,pixel178,pixel179,pixel180,pixel181,pixel182,pixel183,pixel184,pixel185,pixel186,pixel187,pixel188,pixel189,pixel190,pixel191,pixel192,pixel193,pixel194,pixel195,pixel196,pixel197,pixel198,pixel199,pixel200,pixel201,pixel202,pixel203,pixel204,pixel205,pixel206,pixel207,pixel208,pixel209,pixel210,pixel211,pixel212,pixel213,pixel214,pixel215,pixel216,pixel217,pixel218,pixel219,pixel220,pixel221,pixel222,pixel223,pixel224,pixel225,pixel226,pixel227,pixel228,pixel229,pixel230,pixel231,pixel232,pixel233,pixel234,pixel235,pixel236,pixel237,pixel238,pixel239,pixel240,pixel241,pixel242,pixel243,pixel244,pixel245,pixel246,pixel247,pixel248,pixel249,pixel250,pixel251,pixel252,pixel253,pixel254,pixel255,pixel256,pixel257,pixel258,pixel259,pixel260,pixel261,pixel262,pixel263,pixel264,pixel265,pixel266,pixel267,pixel268,pixel269,pixel270,pixel271,pixel272,pixel273,pixel274,pixel275,pixel276,pixel277,pixel278,pixel279,pixel280,pixel281,pixel282,pixel283,pixel284,pixel285,pixel286,pixel287,pixel288,pixel289,pixel290,pixel291,pixel292,pixel293,pixel294,pixel295,pixel296,pixel297,pixel298,pixel299,pixel300,pixel301,pixel302,pixel303,pixel304,pixel305,pixel306,pixel307,pixel308,pixel309,pixel310,pixel311,pixel312,pixel313,pixel314,pixel315,pixel316,pixel317,pixel318,pixel319,pixel320,pixel321,pixel322,pixel323,pixel324,pixel325,pixel326,pixel327,pixel328,pixel329,pixel330,pixel331,pixel332,pixel333,pixel334,pixel335,pixel336,pixel337,pixel338,pixel339,pixel340,pixel341,pixel342,pixel343,pixel344,pixel345,pixel346,pixel347,pixel348,pixel349,pixel350,pixel351,pixel352,pixel353,pixel354,pixel355,pixel356,pixel357,pixel358,pixel359,pixel360,pixel361,pixel362,pixel363,pixel364,pixel365,pixel366,pixel367,pixel368,pixel369,pixel370,pixel371,pixel372,pixel373,pixel374,pixel375,pixel376,pixel377,pixel378,pixel379,pixel380,pixel381,pixel382,pixel383,pixel384,pixel385,pixel386,pixel387,pixel388,pixel389,pixel390,pixel391,pixel392,pixel393,pixel394,pixel395,pixel396,pixel397,pixel398,pixel399,pixel400,pixel401,pixel402,pixel403,pixel404,pixel405,pixel406,pixel407,pixel408,pixel409,pixel410,pixel411,pixel412,pixel413,pixel414,pixel415,pixel416,pixel417,pixel418,pixel419,pixel420,pixel421,pixel422,pixel423,pixel424,pixel425,pixel426,pixel427,pixel428,pixel429,pixel430,pixel431,pixel432,pixel433,pixel434,pixel435,pixel436,pixel437,pixel438,pixel439,pixel440,pixel441,pixel442,pixel443,pixel444,pixel445,pixel446,pixel447,pixel448,pixel449,pixel450,pixel451,pixel452,pixel453,pixel454,pixel455,pixel456,pixel457,pixel458,pixel459,pixel460,pixel461,pixel462,pixel463,pixel464,pixel465,pixel466,pixel467,pixel468,pixel469,pixel470,pixel471,pixel472,pixel473,pixel474,pixel475,pixel476,pixel477,pixel478,pixel479,pixel480,pixel481,pixel482,pixel483,pixel484,pixel485,pixel486,pixel487,pixel488,pixel489,pixel490,pixel491,pixel492,pixel493,pixel494,pixel495,pixel496,pixel497,pixel498,pixel499,pixel500,pixel501,pixel502,pixel503,pixel504,pixel505,pixel506,pixel507,pixel508,pixel509,pixel510,pixel511,pixel512,pixel513,pixel514,pixel515,pixel516,pixel517,pixel518,pixel519,pixel520,pixel521,pixel522,pixel523,pixel524,pixel525,pixel526,pixel527,pixel528,pixel529,pixel530,pixel531,pixel532,pixel533,pixel534,pixel535,pixel536,pixel537,pixel538,pixel539,pixel540,pixel541,pixel542,pixel543,pixel544,pixel545,pixel546,pixel547,pixel548,pixel549,pixel550,pixel551,pixel552,pixel553,pixel554,pixel555,pixel556,pixel557,pixel558,pixel559,pixel560,pixel561,pixel562,pixel563,pixel564,pixel565,pixel566,pixel567,pixel568,pixel569,pixel570,pixel571,pixel572,pixel573,pixel574,pixel575,pixel576,pixel577,pixel578,pixel579,pixel580,pixel581,pixel582,pixel583,pixel584,pixel585,pixel586,pixel587,pixel588,pixel589,pixel590,pixel591,pixel592,pixel593,pixel594,pixel595,pixel596,pixel597,pixel598,pixel599,pixel600,pixel601,pixel602,pixel603,pixel604,pixel605,pixel606,pixel607,pixel608,pixel609,pixel610,pixel611,pixel612,pixel613,pixel614,pixel615,pixel616,pixel617,pixel618,pixel619,pixel620,pixel621,pixel622,pixel623,pixel624,pixel625,pixel626,pixel627,pixel628,pixel629,pixel630,pixel631,pixel632,pixel633,pixel634,pixel635,pixel636,pixel637,pixel638,pixel639,pixel640,pixel641,pixel642,pixel643,pixel644,pixel645,pixel646,pixel647,pixel648,pixel649,pixel650,pixel651,pixel652,pixel653,pixel654,pixel655,pixel656,pixel657,pixel658,pixel659,pixel660,pixel661,pixel662,pixel663,pixel664,pixel665,pixel666,pixel667,pixel668,pixel669,pixel670,pixel671,pixel672,pixel673,pixel674,pixel675,pixel676,pixel677,pixel678,pixel679,pixel680,pixel681,pixel682,pixel683,pixel684,pixel685,pixel686,pixel687,pixel688,pixel689,pixel690,pixel691,pixel692,pixel693,pixel694,pixel695,pixel696,pixel697,pixel698,pixel699,pixel700,pixel701,pixel702,pixel703,pixel704,pixel705,pixel706,pixel707,pixel708,pixel709,pixel710,pixel711,pixel712,pixel713,pixel714,pixel715,pixel716,pixel717,pixel718,pixel719,pixel720,pixel721,pixel722,pixel723,pixel724,pixel725,pixel726,pixel727,pixel728,pixel729,pixel730,pixel731,pixel732,pixel733,pixel734,pixel735,pixel736,pixel737,pixel738,pixel739,pixel740,pixel741,pixel742,pixel743,pixel744,pixel745,pixel746,pixel747,pixel748,pixel749,pixel750,pixel751,pixel752,pixel753,pixel754,pixel755,pixel756,pixel757,pixel758,pixel759,pixel760,pixel761,pixel762,pixel763,pixel764,pixel765,pixel766,pixel767,pixel768,pixel769,pixel770,pixel771,pixel772,pixel773,pixel774,pixel775,pixel776,pixel777,pixel778,pixel779,pixel780,pixel781,pixel782,pixel783,pixel784
Each subsequent line (data points) look like this:
3,107,118,127,134,139,143,146,150,153,156,158,160,163,165,159,166,168,170,170,171,171,171,172,171,171,170,170,169,111,121,129,135,141,144,148,151,154,157,160,163,164,170,119,152,171,171,170,171,172,172,172,172,172,171,171,170,113,123,131,137,142,145,150,152,155,158,161,163,164,172,105,142,170,171,171,171,172,172,173,173,172,171,171,171,116,125,133,139,143,146,151,153,156,159,162,163,167,167,95,144,171,172,172,172,172,172,173,173,173,172,172,171,117,126,134,140,145,149,153,156,158,161,163,164,175,156,87,154,172,173,173,173,173,173,174,174,174,173,172,172,119,128,136,142,146,150,153,156,159,163,165,164,184,148,89,164,172,174,174,174,174,175,175,174,175,174,173,173,122,130,138,143,147,150,154,158,162,165,166,172,181,128,94,170,173,175,174,175,176,177,177,177,177,175,175,174,122,132,139,145,149,152,156,160,163,165,166,181,172,103,113,175,176,178,178,179,179,179,179,178,179,177,175,174,125,134,141,147,150,153,157,161,164,167,168,184,179,116,126,165,176,179,180,180,181,180,180,180,179,178,177,176,128,135,142,148,152,154,158,162,165,168,170,187,180,156,161,124,143,179,178,178,181,182,181,180,181,180,179,179,129,136,144,150,153,155,159,163,166,169,172,187,184,153,102,117,110,175,169,154,182,183,183,182,182,181,181,179,131,138,145,150,155,157,161,165,168,174,190,189,175,146,94,97,113,151,158,129,184,184,184,184,183,183,182,180,131,139,146,151,155,159,163,167,175,182,179,171,159,114,102,89,121,136,136,96,172,186,186,185,185,184,182,181,131,140,147,154,157,160,164,179,186,191,187,180,157,100,88,84,108,111,126,90,120,186,187,187,186,185,184,182,133,141,149,155,158,160,174,201,189,165,151,143,146,120,87,78,87,76,108,98,96,181,188,187,186,186,185,183,133,141,150,156,160,161,179,197,174,135,99,72,95,134,97,72,74,68,116,105,108,187,189,187,187,186,186,185,134,143,151,156,161,163,179,194,156,110,74,42,52,139,94,67,75,75,118,106,129,189,191,190,188,188,187,186,135,144,152,158,163,163,177,193,161,122,84,43,71,134,81,57,71,88,112,98,157,193,193,192,190,190,189,188,136,144,152,158,162,163,176,192,164,128,98,62,60,100,71,76,96,101,105,95,174,195,194,194,194,193,191,190,137,145,152,159,164,165,178,191,164,135,113,82,59,87,98,111,120,108,97,108,190,196,195,195,194,193,193,192,139,146,154,160,164,165,175,186,163,139,112,85,67,102,126,133,126,105,104,176,197,198,197,196,195,195,194,193,138,147,155,161,165,167,172,186,163,137,107,87,76,106,122,125,117,96,156,199,199,200,198,196,196,195,195,194,139,148,156,163,166,168,172,180,158,131,108,99,86,108,118,116,103,107,191,202,201,200,200,200,199,197,198,196,140,149,157,164,168,167,177,178,155,131,118,105,87,100,106,100,96,164,202,202,202,202,202,201,200,199,199,198,140,150,157,165,167,170,181,175,152,130,115,98,82,85,90,99,165,202,203,204,203,203,202,202,201,201,200,200,142,150,159,165,170,191,173,157,144,119,97,84,79,79,91,172,202,203,203,205,204,204,204,203,202,202,201,200,142,151,160,165,188,190,187,150,119,109,85,79,79,78,137,203,205,206,206,207,207,206,206,204,205,204,203,202,142,151,160,172,196,188,188,190,135,96,86,77,77,79,176,205,207,207,207,207,207,207,206,206,206,204,203,202
As you can see, each file includes a header (the first line) and each subsequent data point is represented as a line that contains 785 values.
The first value is the label (the numeric representation of each letter) and the other 784 values are the value of each pixel of the image. Remember that the original images have a resolution of 28x28, which sums up to 784 pixels.
Parsing the dataset
Now complete the parse_data_from_input below.
This function should be able to read a file passed as input and return 2 numpy arrays, one containing the labels and one containing the 28x28 representation of each image within the file. These numpy arrays should have type float64.
A couple of things to keep in mind:
-
The first line contains the column headers, so you should ignore it.
-
Each successive line contains 785 comma-separated values between 0 and 255
-
The first value is the label
-
The rest are the pixel values for that picture
-
Hint:
You have two options to solve this function.
-
-
One is to use
csv.readerand create a for loop that reads from it, if you take this approach take this into consideration:-
csv.readerreturns an iterable that returns a row of the csv file in each iteration. Following this convention, row[0] has the label and row[1:] has the 784 pixel values. -
To reshape the arrays (going from 784 to 28x28), you can use functions such as
np.array_splitornp.reshape. -
For type conversion of the numpy arrays, use the method
np.ndarray.astype.
-
-
-
- The other one is to use
np.loadtxt. You can find the documentation here.
- The other one is to use
Regardless of the method you chose, your function should finish its execution in under 1 minute. If you see that your function is taking a long time to run, try changing your implementation.
# grader-required-cell
# GRADED FUNCTION: parse_data_from_input
def parse_data_from_input(filename):
"""
Parses the images and labels from a CSV file
Args:
filename (string): path to the CSV file
Returns:
images, labels: tuple of numpy arrays containing the images and labels
"""
with open(filename) as file:
### START CODE HERE
# Use csv.reader, passing in the appropriate delimiter
# Remember that csv.reader can be iterated and returns one line in each iteration
csv_reader = csv.reader(file, delimiter=",")
labels = []
images = []
next(csv_reader)
for line in csv_reader:
labels.append(line[0])
images.append(np.reshape(np.array(line[1:]), (28, 28)))
labels = np.array(labels, dtype=np.dtype("float64"))
images = np.array(images, dtype=np.dtype("float64"))
### END CODE HERE
return images, labels
# grader-required-cell
# Test your function
training_images, training_labels = parse_data_from_input(TRAINING_FILE)
validation_images, validation_labels = parse_data_from_input(VALIDATION_FILE)
print(f"Training images has shape: {training_images.shape} and dtype: {training_images.dtype}")
print(f"Training labels has shape: {training_labels.shape} and dtype: {training_labels.dtype}")
print(f"Validation images has shape: {validation_images.shape} and dtype: {validation_images.dtype}")
print(f"Validation labels has shape: {validation_labels.shape} and dtype: {validation_labels.dtype}")
Training images has shape: (27455, 28, 28) and dtype: float64
Training labels has shape: (27455,) and dtype: float64
Validation images has shape: (7172, 28, 28) and dtype: float64
Validation labels has shape: (7172,) and dtype: float64
Expected Output:
Training images has shape: (27455, 28, 28) and dtype: float64
Training labels has shape: (27455,) and dtype: float64
Validation images has shape: (7172, 28, 28) and dtype: float64
Validation labels has shape: (7172,) and dtype: float64
Visualizing the numpy arrays
Now that you have converted the initial csv data into a format that is compatible with computer vision tasks, take a moment to actually see how the images of the dataset look like:
# Plot a sample of 10 images from the training set
def plot_categories(training_images, training_labels):
fig, axes = plt.subplots(1, 10, figsize=(16, 15))
axes = axes.flatten()
letters = list(string.ascii_lowercase)
for k in range(10):
img = training_images[k]
img = np.expand_dims(img, axis=-1)
img = array_to_img(img)
ax = axes[k]
ax.imshow(img, cmap="Greys_r")
ax.set_title(f"{letters[int(training_labels[k])]}")
ax.set_axis_off()
plt.tight_layout()
plt.show()
plot_categories(training_images, training_labels)

Creating the generators for the CNN
Now that you have successfully organized the data in a way that can be easily fed to Keras’ ImageDataGenerator, it is time for you to code the generators that will yield batches of images, both for training and validation. For this complete the train_val_generators function below.
Some important notes:
- The images in this dataset come in the same resolution so you don’t need to set a custom
target_sizein this case. In fact, you can’t even do so because this time you will not be using theflow_from_directorymethod (as in previous assignments). Instead you will use theflowmethod. - You need to add the “color” dimension to the numpy arrays that encode the images. These are black and white images, so this new dimension should have a size of 1 (instead of 3, which is used when dealing with colored images). Take a look at the function
np.expand_dimsfor this.
# grader-required-cell
# GRADED FUNCTION: train_val_generators
def train_val_generators(training_images, training_labels, validation_images, validation_labels):
"""
Creates the training and validation data generators
Args:
training_images (array): parsed images from the train CSV file
training_labels (array): parsed labels from the train CSV file
validation_images (array): parsed images from the test CSV file
validation_labels (array): parsed labels from the test CSV file
Returns:
train_generator, validation_generator - tuple containing the generators
"""
### START CODE HERE
# In this section you will have to add another dimension to the data
# So, for example, if your array is (10000, 28, 28)
# You will need to make it (10000, 28, 28, 1)
# Hint: np.expand_dims
training_images = np.expand_dims(training_images, axis = -1)
validation_images = np.expand_dims(validation_images, axis = -1)
# Instantiate the ImageDataGenerator class
# Don't forget to normalize pixel values
# and set arguments to augment the images (if desired)
train_datagen = ImageDataGenerator(rescale = 1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# Pass in the appropriate arguments to the flow method
train_generator = train_datagen.flow(x=training_images,
y=training_labels,
batch_size=32)
# Instantiate the ImageDataGenerator class (don't forget to set the rescale argument)
# Remember that validation data should not be augmented
validation_datagen = ImageDataGenerator(rescale = 1./255)
# Pass in the appropriate arguments to the flow method
validation_generator = validation_datagen.flow(x=validation_images,
y=validation_labels,
batch_size=32)
### END CODE HERE
return train_generator, validation_generator
# grader-required-cell
# Test your generators
train_generator, validation_generator = train_val_generators(training_images, training_labels, validation_images, validation_labels)
print(f"Images of training generator have shape: {train_generator.x.shape}")
print(f"Labels of training generator have shape: {train_generator.y.shape}")
print(f"Images of validation generator have shape: {validation_generator.x.shape}")
print(f"Labels of validation generator have shape: {validation_generator.y.shape}")
Images of training generator have shape: (27455, 28, 28, 1)
Labels of training generator have shape: (27455,)
Images of validation generator have shape: (7172, 28, 28, 1)
Labels of validation generator have shape: (7172,)
Expected Output:
Images of training generator have shape: (27455, 28, 28, 1)
Labels of training generator have shape: (27455,)
Images of validation generator have shape: (7172, 28, 28, 1)
Labels of validation generator have shape: (7172,)
Coding the CNN
One last step before training is to define the architecture of the model that will be trained.
Complete the create_model function below. This function should return a Keras’ model that uses the Sequential or the Functional API.
The last layer of your model should have a number of units that corresponds to the number of possible categories, as well as the correct activation function.
Aside from defining the architecture of the model, you should also compile it so make sure to use a loss function that is suitable for multi-class classification.
Note that you should use no more than 2 Conv2D and 2 MaxPooling2D layers to achieve the desired performance.
# grader-required-cell
def create_model():
### START CODE HERE
# Define the model
# Use no more than 2 Conv2D and 2 MaxPooling2D
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, (3, 3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
# Flatten
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
# 26 classes
tf.keras.layers.Dense(26, activation='softmax')
])
model.compile(optimizer = tf.optimizers.Adam(),
loss = "sparse_categorical_crossentropy",
metrics=["accuracy"])
### END CODE HERE
return model
# Save your model
model = create_model()
# Train your model
history = model.fit(train_generator,
epochs=15,
validation_data=validation_generator)
Epoch 1/15
858/858 [==============================] - 19s 17ms/step - loss: 2.6373 - accuracy: 0.1891 - val_loss: 1.7337 - val_accuracy: 0.4260
Epoch 2/15
858/858 [==============================] - 14s 16ms/step - loss: 1.8195 - accuracy: 0.4134 - val_loss: 1.0922 - val_accuracy: 0.5975
Epoch 3/15
858/858 [==============================] - 14s 16ms/step - loss: 1.3986 - accuracy: 0.5435 - val_loss: 0.8532 - val_accuracy: 0.6842
Epoch 4/15
858/858 [==============================] - 15s 18ms/step - loss: 1.1317 - accuracy: 0.6249 - val_loss: 0.7609 - val_accuracy: 0.7264
Epoch 5/15
858/858 [==============================] - 15s 17ms/step - loss: 0.9647 - accuracy: 0.6785 - val_loss: 0.6321 - val_accuracy: 0.7556
Epoch 6/15
858/858 [==============================] - 14s 16ms/step - loss: 0.8439 - accuracy: 0.7172 - val_loss: 0.5356 - val_accuracy: 0.7943
Epoch 7/15
858/858 [==============================] - 14s 17ms/step - loss: 0.7638 - accuracy: 0.7472 - val_loss: 0.4782 - val_accuracy: 0.8310
Epoch 8/15
858/858 [==============================] - 15s 17ms/step - loss: 0.6958 - accuracy: 0.7651 - val_loss: 0.4509 - val_accuracy: 0.8356
Epoch 9/15
858/858 [==============================] - 14s 16ms/step - loss: 0.6327 - accuracy: 0.7885 - val_loss: 0.3695 - val_accuracy: 0.8572
Epoch 10/15
858/858 [==============================] - 15s 17ms/step - loss: 0.5788 - accuracy: 0.8072 - val_loss: 0.2097 - val_accuracy: 0.9311
Epoch 11/15
858/858 [==============================] - 14s 16ms/step - loss: 0.5446 - accuracy: 0.8195 - val_loss: 0.2663 - val_accuracy: 0.8997
Epoch 12/15
858/858 [==============================] - 14s 16ms/step - loss: 0.5084 - accuracy: 0.8311 - val_loss: 0.2161 - val_accuracy: 0.9272
Epoch 13/15
858/858 [==============================] - 15s 17ms/step - loss: 0.4883 - accuracy: 0.8354 - val_loss: 0.2001 - val_accuracy: 0.9335
Epoch 14/15
858/858 [==============================] - 14s 16ms/step - loss: 0.4553 - accuracy: 0.8480 - val_loss: 0.2082 - val_accuracy: 0.9202
Epoch 15/15
858/858 [==============================] - 14s 17ms/step - loss: 0.4370 - accuracy: 0.8534 - val_loss: 0.2580 - val_accuracy: 0.9077
Now take a look at your training history:
# Plot the chart for accuracy and loss on both training and validation
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'r', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'r', label='Training Loss')
plt.plot(epochs, val_loss, 'b', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
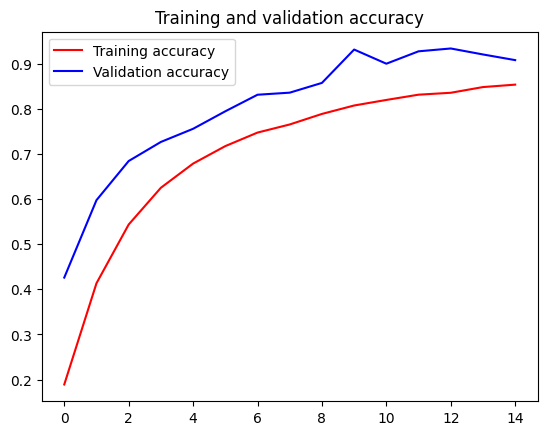
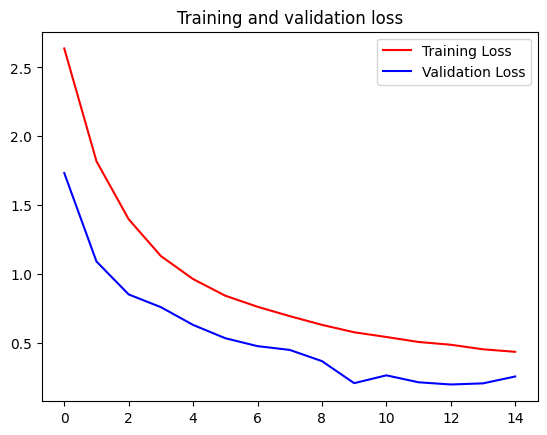
You will not be graded based on the accuracy of your model but try making it as high as possible for both training and validation, as an optional exercise, after submitting your notebook for grading.
A reasonable benchmark is to achieve over 99% accuracy for training and over 95% accuracy for validation within 15 epochs. Try tweaking your model’s architecture or the augmentation techniques to see if you can achieve these levels of accuracy.
Download your notebook for grading
You will need to submit your solution notebook for grading. The following code cells will check if this notebook’s grader metadata (i.e. hidden data in the notebook needed for grading) is not modified by your workspace. This will ensure that the autograder can evaluate your code properly. Depending on its output, you will either:
- if the metadata is intact: Download the current notebook. Click on the File tab on the upper left corner of the screen then click on
Download -> Download .ipynb.You can name it anything you want as long as it is a valid.ipynb(jupyter notebook) file.
- if the metadata is missing: A new notebook with your solutions will be created on this Colab workspace. It should be downloaded automatically and you can submit that to the grader.
# Download metadata checker
!wget -nc https://storage.googleapis.com/tensorflow-1-public/colab_metadata_checker.py
--2023-06-02 08:50:03-- https://storage.googleapis.com/tensorflow-1-public/colab_metadata_checker.py
Resolving storage.googleapis.com (storage.googleapis.com)... 173.194.74.128, 173.194.192.128, 209.85.145.128, ...
Connecting to storage.googleapis.com (storage.googleapis.com)|173.194.74.128|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1997 (2.0K) [text/x-python-script]
Saving to: ‘colab_metadata_checker.py’
colab_metadata_chec 100%[===================>] 1.95K --.-KB/s in 0s
2023-06-02 08:50:03 (38.9 MB/s) - ‘colab_metadata_checker.py’ saved [1997/1997]
import colab_metadata_checker
# Please see the output of this cell to see which file you need to submit to the grader
colab_metadata_checker.run('C2W4_Assignment_fixed.ipynb')
Grader metadata detected! You can download this notebook by clicking `File > Download > Download as .ipynb` and submit it to the grader!
Please disregard the following note if the notebook metadata is detected
Note: Just in case the download fails for the second point above, you can also do these steps:
- Click the Folder icon on the left side of this screen to open the File Manager.
- Click the Folder Refresh icon in the File Manager to see the latest files in the workspace. You should see a file ending with a
_fixed.ipynb. - Right-click on that file to save locally and submit it to the grader.
Congratulations on finishing this week’s assignment!
You have successfully implemented a convolutional neural network that is able to perform multi-class classification tasks! Nice job!
Keep it up!