Coursera
Week 1: Using CNN’s with the Cats vs Dogs Dataset
Welcome to the 1st assignment of the course! This week, you will be using the famous Cats vs Dogs dataset to train a model that can classify images of dogs from images of cats. For this, you will create your own Convolutional Neural Network in Tensorflow and leverage Keras’ image preprocessing utilities.
You will also create some helper functions to move the images around the filesystem so if you are not familiar with the os module be sure to take a look a the docs.
Let’s get started!
NOTE: To prevent errors from the autograder, pleave avoid editing or deleting non-graded cells in this notebook . Please only put your solutions in between the ### START CODE HERE and ### END CODE HERE code comments, and refrain from adding any new cells.
# grader-required-cell
import os
import zipfile
import random
import shutil
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from shutil import copyfile
import matplotlib.pyplot as plt
Download the dataset from its original source by running the cell below.
Note that the zip file that contains the images is unzipped under the /tmp directory.
# If the URL doesn't work, visit https://www.microsoft.com/en-us/download/confirmation.aspx?id=54765
# And right click on the 'Download Manually' link to get a new URL to the dataset
# Note: This is a very large dataset and will take some time to download
!wget --no-check-certificate \
"https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_5340.zip" \
-O "/tmp/cats-and-dogs.zip"
local_zip = '/tmp/cats-and-dogs.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp')
zip_ref.close()
--2023-06-01 15:56:04-- https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_5340.zip
Resolving download.microsoft.com (download.microsoft.com)... 104.97.45.22, 2600:1409:9800:984::317f, 2600:1409:9800:98c::317f
Connecting to download.microsoft.com (download.microsoft.com)|104.97.45.22|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 824887076 (787M) [application/octet-stream]
Saving to: ‘/tmp/cats-and-dogs.zip’
/tmp/cats-and-dogs. 100%[===================>] 786.67M 125MB/s in 6.5s
2023-06-01 15:56:10 (120 MB/s) - ‘/tmp/cats-and-dogs.zip’ saved [824887076/824887076]
Now the images are stored within the /tmp/PetImages directory. There is a subdirectory for each class, so one for dogs and one for cats.
# grader-required-cell
source_path = '/tmp/PetImages'
source_path_dogs = os.path.join(source_path, 'Dog')
source_path_cats = os.path.join(source_path, 'Cat')
# Deletes all non-image files (there are two .db files bundled into the dataset)
!find /tmp/PetImages/ -type f ! -name "*.jpg" -exec rm {} +
# os.listdir returns a list containing all files under the given path
print(f"There are {len(os.listdir(source_path_dogs))} images of dogs.")
print(f"There are {len(os.listdir(source_path_cats))} images of cats.")
There are 12500 images of dogs.
There are 12500 images of cats.
Expected Output:
There are 12500 images of dogs.
There are 12500 images of cats.
You will need a directory for cats-v-dogs, and subdirectories for training
and validation. These in turn will need subdirectories for ‘cats’ and ‘dogs’. To accomplish this, complete the create_train_val_dirs below:
# grader-required-cell
# Define root directory
root_dir = '/tmp/cats-v-dogs'
# Empty directory to prevent FileExistsError is the function is run several times
if os.path.exists(root_dir):
shutil.rmtree(root_dir)
# GRADED FUNCTION: create_train_val_dirs
def create_train_val_dirs(root_path):
"""
Creates directories for the train and test sets
Args:
root_path (string) - the base directory path to create subdirectories from
Returns:
None
"""
### START CODE HERE
# HINT:
# Use os.makedirs to create your directories with intermediate subdirectories
# Don't hardcode the paths. Use os.path.join to append the new directories to the root_path parameter
os.makedirs(os.path.join(root_path, "training/dogs"))
os.makedirs(os.path.join(root_path, "training/cats"))
os.makedirs(os.path.join(root_path, "validation/dogs"))
os.makedirs(os.path.join(root_path, "validation/cats"))
### END CODE HERE
try:
create_train_val_dirs(root_path=root_dir)
except FileExistsError:
print("You should not be seeing this since the upper directory is removed beforehand")
# grader-required-cell
# Test your create_train_val_dirs function
for rootdir, dirs, files in os.walk(root_dir):
for subdir in dirs:
print(os.path.join(rootdir, subdir))
/tmp/cats-v-dogs/validation
/tmp/cats-v-dogs/training
/tmp/cats-v-dogs/validation/dogs
/tmp/cats-v-dogs/validation/cats
/tmp/cats-v-dogs/training/dogs
/tmp/cats-v-dogs/training/cats
Expected Output (directory order might vary):
>/tmp/cats-v-dogs/training
/tmp/cats-v-dogs/validation
/tmp/cats-v-dogs/training/cats
/tmp/cats-v-dogs/training/dogs
/tmp/cats-v-dogs/validation/cats
/tmp/cats-v-dogs/validation/dogs
Code the split_data function which takes in the following arguments:
-
SOURCE_DIR: directory containing the files
-
TRAINING_DIR: directory that a portion of the files will be copied to (will be used for training)
-
VALIDATION_DIR: directory that a portion of the files will be copied to (will be used for validation)
-
SPLIT_SIZE: determines the portion of images used for training.
The files should be randomized, so that the training set is a random sample of the files, and the validation set is made up of the remaining files.
For example, if SOURCE_DIR is PetImages/Cat, and SPLIT_SIZE is .9 then 90% of the images in PetImages/Cat will be copied to the TRAINING_DIR directory
and 10% of the images will be copied to the VALIDATION_DIR directory.
All images should be checked before the copy, so if they have a zero file length, they will be omitted from the copying process. If this is the case then your function should print out a message such as "filename is zero length, so ignoring.". You should perform this check before the split so that only non-zero images are considered when doing the actual split.
Hints:
-
os.listdir(DIRECTORY)returns a list with the contents of that directory. -
os.path.getsize(PATH)returns the size of the file -
copyfile(source, destination)copies a file from source to destination -
random.sample(list, len(list))shuffles a list
# grader-required-cell
# GRADED FUNCTION: split_data
def split_data(SOURCE_DIR, TRAINING_DIR, VALIDATION_DIR, SPLIT_SIZE):
"""
Splits the data into train and test sets
Args:
SOURCE_DIR (string): directory path containing the images
TRAINING_DIR (string): directory path to be used for training
VALIDATION_DIR (string): directory path to be used for validation
SPLIT_SIZE (float): proportion of the dataset to be used for training
Returns:
None
"""
### START CODE HERE
files = []
for filename in os.listdir(SOURCE_DIR):
current_file = os.path.join(SOURCE_DIR, filename)
if os.path.getsize(current_file) > 0:
files.append(filename)
else:
print(f'{filename} is zero length, so ignoring.')
training_length = int(len(files) * SPLIT_SIZE)
testing_length = int(len(files) - training_length)
shuffled_set = random.sample(files, len(files))
training_set = shuffled_set[0:training_length]
testing_set = shuffled_set[-testing_length:]
for filename in training_set:
src_file = os.path.join(SOURCE_DIR, filename)
dest_file = os.path.join(TRAINING_DIR, filename)
copyfile(src_file, dest_file)
for filename in testing_set:
src_file = os.path.join(SOURCE_DIR, filename)
dest_file = os.path.join(VALIDATION_DIR, filename)
copyfile(src_file, dest_file)
### END CODE HERE
# grader-required-cell
# Test your split_data function
# Define paths
CAT_SOURCE_DIR = "/tmp/PetImages/Cat/"
DOG_SOURCE_DIR = "/tmp/PetImages/Dog/"
TRAINING_DIR = "/tmp/cats-v-dogs/training/"
VALIDATION_DIR = "/tmp/cats-v-dogs/validation/"
TRAINING_CATS_DIR = os.path.join(TRAINING_DIR, "cats/")
VALIDATION_CATS_DIR = os.path.join(VALIDATION_DIR, "cats/")
TRAINING_DOGS_DIR = os.path.join(TRAINING_DIR, "dogs/")
VALIDATION_DOGS_DIR = os.path.join(VALIDATION_DIR, "dogs/")
# Empty directories in case you run this cell multiple times
if len(os.listdir(TRAINING_CATS_DIR)) > 0:
for file in os.scandir(TRAINING_CATS_DIR):
os.remove(file.path)
if len(os.listdir(TRAINING_DOGS_DIR)) > 0:
for file in os.scandir(TRAINING_DOGS_DIR):
os.remove(file.path)
if len(os.listdir(VALIDATION_CATS_DIR)) > 0:
for file in os.scandir(VALIDATION_CATS_DIR):
os.remove(file.path)
if len(os.listdir(VALIDATION_DOGS_DIR)) > 0:
for file in os.scandir(VALIDATION_DOGS_DIR):
os.remove(file.path)
# Define proportion of images used for training
split_size = .9
# Run the function
# NOTE: Messages about zero length images should be printed out
split_data(CAT_SOURCE_DIR, TRAINING_CATS_DIR, VALIDATION_CATS_DIR, split_size)
split_data(DOG_SOURCE_DIR, TRAINING_DOGS_DIR, VALIDATION_DOGS_DIR, split_size)
# Check that the number of images matches the expected output
# Your function should perform copies rather than moving images so original directories should contain unchanged images
print(f"\n\nOriginal cat's directory has {len(os.listdir(CAT_SOURCE_DIR))} images")
print(f"Original dog's directory has {len(os.listdir(DOG_SOURCE_DIR))} images\n")
# Training and validation splits
print(f"There are {len(os.listdir(TRAINING_CATS_DIR))} images of cats for training")
print(f"There are {len(os.listdir(TRAINING_DOGS_DIR))} images of dogs for training")
print(f"There are {len(os.listdir(VALIDATION_CATS_DIR))} images of cats for validation")
print(f"There are {len(os.listdir(VALIDATION_DOGS_DIR))} images of dogs for validation")
666.jpg is zero length, so ignoring.
11702.jpg is zero length, so ignoring.
Original cat's directory has 12500 images
Original dog's directory has 12500 images
There are 11249 images of cats for training
There are 11249 images of dogs for training
There are 1250 images of cats for validation
There are 1250 images of dogs for validation
Expected Output:
666.jpg is zero length, so ignoring.
11702.jpg is zero length, so ignoring.
Original cat's directory has 12500 images
Original dog's directory has 12500 images
There are 11249 images of cats for training
There are 11249 images of dogs for training
There are 1250 images of cats for validation
There are 1250 images of dogs for validation
Now that you have successfully organized the data in a way that can be easily fed to Keras’ ImageDataGenerator, it is time for you to code the generators that will yield batches of images, both for training and validation. For this, complete the train_val_generators function below.
Something important to note is that the images in this dataset come in a variety of resolutions. Luckily, the flow_from_directory method allows you to standarize this by defining a tuple called target_size that will be used to convert each image to this target resolution. For this exercise, use a target_size of (150, 150).
Hint:
Don’t use data augmentation by setting extra parameters when you instantiate the ImageDataGenerator class. This will make the training of your model to take longer to reach the necessary accuracy threshold to pass this assignment and this topic will be covered in the next week.
# grader-required-cell
# GRADED FUNCTION: train_val_generators
def train_val_generators(TRAINING_DIR, VALIDATION_DIR):
"""
Creates the training and validation data generators
Args:
TRAINING_DIR (string): directory path containing the training images
VALIDATION_DIR (string): directory path containing the testing/validation images
Returns:
train_generator, validation_generator - tuple containing the generators
"""
### START CODE HERE
# Instantiate the ImageDataGenerator class (don't forget to set the rescale argument)
train_datagen = ImageDataGenerator(rescale=1.0/255)
# Pass in the appropriate arguments to the flow_from_directory method
train_generator = train_datagen.flow_from_directory(directory=TRAINING_DIR,
batch_size=100,
class_mode="binary",
target_size=(150, 150))
# Instantiate the ImageDataGenerator class (don't forget to set the rescale argument)
validation_datagen = ImageDataGenerator(rescale=1.0/255.)
# Pass in the appropriate arguments to the flow_from_directory method
validation_generator = validation_datagen.flow_from_directory(directory=VALIDATION_DIR,
batch_size=100,
class_mode="binary",
target_size=(150, 150))
### END CODE HERE
return train_generator, validation_generator
# grader-required-cell
# Test your generators
train_generator, validation_generator = train_val_generators(TRAINING_DIR, VALIDATION_DIR)
Found 22498 images belonging to 2 classes.
Found 2500 images belonging to 2 classes.
Expected Output:
Found 22498 images belonging to 2 classes.
Found 2500 images belonging to 2 classes.
One last step before training is to define the architecture of the model that will be trained.
Complete the create_model function below which should return a Keras’ Sequential model.
Aside from defining the architecture of the model, you should also compile it so make sure to use a loss function that is compatible with the class_mode you defined in the previous exercise, which should also be compatible with the output of your network. You can tell if they aren’t compatible if you get an error during training.
Note that you should use at least 3 convolution layers to achieve the desired performance.
# grader-required-cell
# GRADED FUNCTION: create_model
def create_model():
# DEFINE A KERAS MODEL TO CLASSIFY CATS V DOGS
# USE AT LEAST 3 CONVOLUTION LAYERS
### START CODE HERE
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16,(3,3), activation = 'relu', input_shape=(150,150,3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32,(3,3), activation = 'relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64,(3,3), activation = 'relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation = 'relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer=tf.keras.optimizers.RMSprop(learning_rate=0.001),
loss="binary_crossentropy",
metrics=['accuracy'])
### END CODE HERE
return model
Now it is time to train your model!
Note: You can ignore the UserWarning: Possibly corrupt EXIF data. warnings.
# Get the untrained model
model = create_model()
# Train the model
# Note that this may take some time.
history = model.fit(train_generator,
epochs=15,
verbose=1,
validation_data=validation_generator)
Epoch 1/15
183/225 [=======================>......] - ETA: 12s - loss: 0.6810 - accuracy: 0.6069
/usr/local/lib/python3.10/dist-packages/PIL/TiffImagePlugin.py:819: UserWarning: Truncated File Read
warnings.warn(str(msg))
225/225 [==============================] - 89s 346ms/step - loss: 0.6640 - accuracy: 0.6210 - val_loss: 0.6542 - val_accuracy: 0.6356
Epoch 2/15
225/225 [==============================] - 80s 356ms/step - loss: 0.5444 - accuracy: 0.7186 - val_loss: 0.4990 - val_accuracy: 0.7596
Epoch 3/15
225/225 [==============================] - 76s 338ms/step - loss: 0.4751 - accuracy: 0.7713 - val_loss: 0.4411 - val_accuracy: 0.7916
Epoch 4/15
225/225 [==============================] - 77s 342ms/step - loss: 0.4255 - accuracy: 0.8031 - val_loss: 0.4322 - val_accuracy: 0.8044
Epoch 5/15
225/225 [==============================] - 77s 344ms/step - loss: 0.3822 - accuracy: 0.8275 - val_loss: 0.4209 - val_accuracy: 0.8144
Epoch 6/15
225/225 [==============================] - 77s 342ms/step - loss: 0.3283 - accuracy: 0.8566 - val_loss: 0.4450 - val_accuracy: 0.8060
Epoch 7/15
225/225 [==============================] - 78s 344ms/step - loss: 0.2787 - accuracy: 0.8806 - val_loss: 0.4132 - val_accuracy: 0.8220
Epoch 8/15
225/225 [==============================] - 78s 348ms/step - loss: 0.2104 - accuracy: 0.9152 - val_loss: 0.4732 - val_accuracy: 0.8156
Epoch 9/15
225/225 [==============================] - 78s 346ms/step - loss: 0.1476 - accuracy: 0.9435 - val_loss: 0.5004 - val_accuracy: 0.8260
Epoch 10/15
225/225 [==============================] - 83s 371ms/step - loss: 0.0932 - accuracy: 0.9678 - val_loss: 0.6336 - val_accuracy: 0.8080
Epoch 11/15
225/225 [==============================] - 81s 359ms/step - loss: 0.0615 - accuracy: 0.9814 - val_loss: 0.7104 - val_accuracy: 0.8128
Epoch 12/15
225/225 [==============================] - 81s 361ms/step - loss: 0.0617 - accuracy: 0.9817 - val_loss: 0.6165 - val_accuracy: 0.8244
Epoch 13/15
225/225 [==============================] - 79s 351ms/step - loss: 0.0314 - accuracy: 0.9912 - val_loss: 0.7871 - val_accuracy: 0.8308
Epoch 14/15
225/225 [==============================] - 78s 345ms/step - loss: 0.0437 - accuracy: 0.9886 - val_loss: 0.8809 - val_accuracy: 0.8268
Epoch 15/15
225/225 [==============================] - 78s 348ms/step - loss: 0.0503 - accuracy: 0.9872 - val_loss: 0.8981 - val_accuracy: 0.8256
Once training has finished, you can run the following cell to check the training and validation accuracy achieved at the end of each epoch.
To pass this assignment, your model should achieve a training accuracy of at least 95% and a validation accuracy of at least 80%. If your model didn’t achieve these thresholds, try training again with a different model architecture and remember to use at least 3 convolutional layers.
#-----------------------------------------------------------
# Retrieve a list of list results on training and test data
# sets for each training epoch
#-----------------------------------------------------------
acc=history.history['accuracy']
val_acc=history.history['val_accuracy']
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=range(len(acc)) # Get number of epochs
#------------------------------------------------
# Plot training and validation accuracy per epoch
#------------------------------------------------
plt.plot(epochs, acc, 'r', "Training Accuracy")
plt.plot(epochs, val_acc, 'b', "Validation Accuracy")
plt.title('Training and validation accuracy')
plt.show()
print("")
#------------------------------------------------
# Plot training and validation loss per epoch
#------------------------------------------------
plt.plot(epochs, loss, 'r', "Training Loss")
plt.plot(epochs, val_loss, 'b', "Validation Loss")
plt.show()
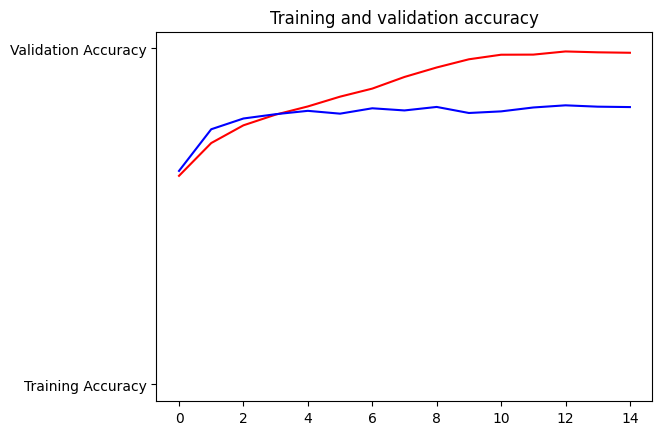
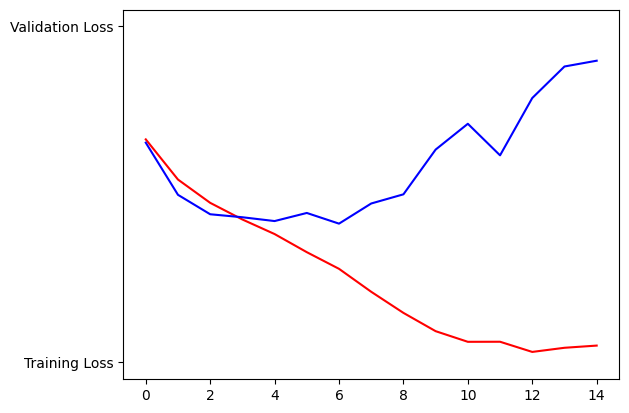
You will probably encounter that the model is overfitting, which means that it is doing a great job at classifying the images in the training set but struggles with new data. This is perfectly fine and you will learn how to mitigate this issue in the upcoming week.
Before downloading this notebook and closing the assignment, be sure to also download the history.pkl file which contains the information of the training history of your model. You can download this file by running the cell below:
def download_history():
import pickle
from google.colab import files
with open('history.pkl', 'wb') as f:
pickle.dump(history.history, f)
files.download('history.pkl')
download_history()
<IPython.core.display.Javascript object>
<IPython.core.display.Javascript object>
Download your notebook for grading
Along with the history.pkl file, you will also need to submit your solution notebook for grading. The following code cells will check if this notebook’s grader metadata (i.e. hidden data in the notebook needed for grading) is not modified by your workspace. This will ensure that the autograder can evaluate your code properly. Depending on its output, you will either:
- if the metadata is intact: Download the current notebook. Click on the File tab on the upper left corner of the screen then click on
Download -> Download .ipynb.You can name it anything you want as long as it is a valid.ipynb(jupyter notebook) file.
- if the metadata is missing: A new notebook with your solutions will be created on this Colab workspace. It should be downloaded automatically and you can submit that to the grader.
# Download metadata checker
!wget -nc https://storage.googleapis.com/tensorflow-1-public/colab_metadata_checker.py
--2023-06-01 16:16:46-- https://storage.googleapis.com/tensorflow-1-public/colab_metadata_checker.py
Resolving storage.googleapis.com (storage.googleapis.com)... 142.250.107.128, 74.125.20.128, 108.177.98.128, ...
Connecting to storage.googleapis.com (storage.googleapis.com)|142.250.107.128|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1997 (2.0K) [text/x-python-script]
Saving to: ‘colab_metadata_checker.py’
colab_metadata_chec 100%[===================>] 1.95K --.-KB/s in 0s
2023-06-01 16:16:46 (44.1 MB/s) - ‘colab_metadata_checker.py’ saved [1997/1997]
import colab_metadata_checker
# Please see the output of this cell to see which file you need to submit to the grader
colab_metadata_checker.run('C2W1_Assignment_fixed.ipynb')
Grader metadata detected! You can download this notebook by clicking `File > Download > Download as .ipynb` and submit it to the grader!
Please disregard the following note if the notebook metadata is detected
Note: Just in case the download fails for the second point above, you can also do these steps:
- Click the Folder icon on the left side of this screen to open the File Manager.
- Click the Folder Refresh icon in the File Manager to see the latest files in the workspace. You should see a file ending with a
_fixed.ipynb. - Right-click on that file to save locally and submit it to the grader.
Congratulations on finishing this week’s assignment!
You have successfully implemented a convolutional neural network that classifies images of cats and dogs, along with the helper functions needed to pre-process the images!
Keep it up!