Coursera
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
Converting a Keras Model to JSON Format
In the previous lesson, you saw how to use a CNN to make your recognition of the handwriting digits more efficient. Now you’ll take that to the next level: recognizing real images of cats and dogs to classify an incoming image as one or the other. In particular, the handwriting recognition made your life a little easier by having all the images be the same size and shape, and they were all monochrome color. Real-world images aren’t like that – they’re in different shapes, aspect ratios etc, and they’re usually in color!
So, as part of the task you need to process your data – not least resizing it to be uniform in shape.
You’ll follow these steps:
- Explore the example data of cats and dogs.
- Build and train a neural network to recognize the difference between the two.
- Evaluate the training and validation accuracy.
- Save the trained model as a Keras HDF5 file.
- Use the tensorflow.js converter to convert the saved Keras model into JSON format.
Import Tensorflow
NOTE: You need to use Tensorflow v2.2 in this lab for compatibility with the autograder. Please be aware of this in case you decide to use your own machine or Google Colab. To complete the requirements for this course, we recommend using the Coursera Lab environment first to avoid grader errors about incompatible models. Once you’ve passed it, feel free to export the notebook to another machine with a more recent Tensorflow version. Most, if not all, of the commands will stay the same but the model output will be a bit different in later versions.
import tensorflow as tf
# This should show version 2.2 to match the autograder
print('\u2022 Using TensorFlow Version:', tf.__version__)
• Using TensorFlow Version: 2.2.0
Explore the Example Data
We’ll be using only 2,000 images taken from the original “Dogs vs. Cats” dataset dataset available on Kaggle, which contains 25,000 images. Here, we use a subset of the full dataset to decrease training time for educational purposes.
These are saved in your workspace under the ./data/cats_and_dogs_filtered folder. This contains train and validation subdirectories for the training and validation datasets (see the Machine Learning Crash Course for a refresher on training, validation, and test sets), which in turn each contain cats and dogs subdirectories.
In short: The training set is the data that is used to tell the neural network model that ‘this is what a cat looks like’, ‘this is what a dog looks like’ etc. The validation data set is images of cats and dogs that the neural network will not see as part of the training, so you can test how well or how badly it does in evaluating if an image contains a cat or a dog.
One thing to pay attention to in this sample: We do not explicitly label the images as cats or dogs. If you remember with the handwriting example earlier, we had labelled ‘this is a 1’, ‘this is a 7’ etc. Later you’ll see something called an ImageGenerator being used – and this is coded to read images from subdirectories, and automatically label them from the name of that subdirectory. So, for example, you will have a ‘training’ directory containing a ‘cats’ directory and a ‘dogs’ one. ImageGenerator will label the images appropriately for you, reducing a coding step.
Let’s define each of these directories:
import os
base_dir = './data/cats_and_dogs_filtered'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# Directory with our training cat/dog pictures
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
# Directory with our validation cat/dog pictures
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
Now, let’s see what the filenames look like in the cats and dogs train directories (file naming conventions are the same in the validation directory):
train_cat_fnames = os.listdir( train_cats_dir )
train_dog_fnames = os.listdir( train_dogs_dir )
print(train_cat_fnames[:10])
print(train_dog_fnames[:10])
['cat.227.jpg', 'cat.308.jpg', 'cat.146.jpg', 'cat.623.jpg', 'cat.74.jpg', 'cat.461.jpg', 'cat.704.jpg', 'cat.380.jpg', 'cat.542.jpg', 'cat.263.jpg']
['dog.702.jpg', 'dog.540.jpg', 'dog.90.jpg', 'dog.621.jpg', 'dog.18.jpg', 'dog.225.jpg', 'dog.144.jpg', 'dog.306.jpg', 'dog.900.jpg', 'dog.108.jpg']
Let’s find out the total number of cat and dog images in the train and validation directories:
print('total training cat images :', len(os.listdir( train_cats_dir ) ))
print('total training dog images :', len(os.listdir( train_dogs_dir ) ))
print('total validation cat images :', len(os.listdir( validation_cats_dir ) ))
print('total validation dog images :', len(os.listdir( validation_dogs_dir ) ))
total training cat images : 1000
total training dog images : 1000
total validation cat images : 500
total validation dog images : 500
For both cats and dogs, we have 1,000 training images and 500 validation images.
Now let’s take a look at a few pictures to get a better sense of what the cat and dog datasets look like. First, we configure the matplotlib parameters:
%matplotlib inline
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
# Parameters for our graph; we'll output images in a 4x4 configuration
nrows = 4
ncols = 4
pic_index = 0 # Index for iterating over images
Now, we display a batch of 8 cat and 8 dog pictures. You can re-run the cell to see a fresh batch each time:
# Set up matplotlib fig, and size it to fit 4x4 pics
fig = plt.gcf()
fig.set_size_inches(ncols*4, nrows*4)
pic_index+=8
next_cat_pix = [os.path.join(train_cats_dir, fname)
for fname in train_cat_fnames[ pic_index-8:pic_index]
]
next_dog_pix = [os.path.join(train_dogs_dir, fname)
for fname in train_dog_fnames[ pic_index-8:pic_index]
]
for i, img_path in enumerate(next_cat_pix+next_dog_pix):
# Set up subplot; subplot indices start at 1
sp = plt.subplot(nrows, ncols, i + 1)
sp.axis('Off') # Don't show axes (or gridlines)
img = mpimg.imread(img_path)
plt.imshow(img)
plt.show()

It may not be obvious from looking at the images in this grid, but an important note here, and a significant difference from the previous lesson is that these images come in all shapes and sizes. When you did the handwriting recognition example, you had 28x28 greyscale images to work with. These are color and in a variety of shapes. Before training a Neural network with them you’ll need to tweak the images. You’ll see that in the next section.
Ok, now that you have an idea for what your data looks like, the next step is to define the model that will be trained to recognize cats or dogs from these images
Building a Small Model from Scratch to Get to ~72% Accuracy
In the previous section you saw that the images were in a variety of shapes and sizes. In order to train a neural network to handle them you’ll need them to be in a uniform size. We’ve chosen 150x150 for this, and you’ll see the code that preprocesses the images to that shape shortly.
But before we continue, let’s start defining the model. We will define a Sequential layer as before, adding some convolutional layers first. Note the input shape parameter this time. In the earlier example it was 28x28x1, because the image was 28x28 in greyscale (8 bits, 1 byte for color depth). This time it is 150x150 for the size and 3 (24 bits, 3 bytes) for the color depth.
We then add a couple of convolutional layers as in the previous example, and flatten the final result to feed into the densely connected layers.
Finally we add the densely connected layers.
Note that because we are facing a two-class classification problem, i.e. a binary classification problem, we will end our network with a sigmoid activation, so that the output of our network will be a single scalar between 0 and 1, encoding the probability that the current image is class 1 (as opposed to class 0).
model = tf.keras.models.Sequential([
# Note the input shape is the desired size of the image 150x150 with 3 bytes color
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# Flatten the results to feed into a DNN
tf.keras.layers.Flatten(),
# 512 neuron hidden layer
tf.keras.layers.Dense(512, activation='relu'),
# Only 1 output neuron. It will contain a value from 0-1 where 0 for 1 class ('cats') and 1 for the other ('dogs')
tf.keras.layers.Dense(1, activation='sigmoid')
])
The model.summary() method call prints a summary of the NN
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 148, 148, 16) 448
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 74, 74, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 72, 72, 32) 4640
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 36, 36, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 34, 34, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 17, 17, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 18496) 0
_________________________________________________________________
dense (Dense) (None, 512) 9470464
_________________________________________________________________
dense_1 (Dense) (None, 1) 513
=================================================================
Total params: 9,494,561
Trainable params: 9,494,561
Non-trainable params: 0
_________________________________________________________________
The “output shape” column shows how the size of your feature map evolves in each successive layer. The convolution layers reduce the size of the feature maps by a bit due to padding, and each pooling layer halves the dimensions.
Next, we’ll configure the specifications for model training. We will train our model with the binary_crossentropy loss, because it’s a binary classification problem and our final activation is a sigmoid. (For a refresher on loss metrics, see the Machine Learning Crash Course.) We will use the rmsprop optimizer with a learning rate of 0.001. During training, we will want to monitor classification accuracy.
NOTE: In this case, using the RMSprop optimization algorithm is preferable to stochastic gradient descent (SGD), because RMSprop automates learning-rate tuning for us. (Other optimizers, such as Adam and Adagrad, also automatically adapt the learning rate during training, and would work equally well here.)
from tensorflow.keras.optimizers import RMSprop
model.compile(optimizer=RMSprop(learning_rate=0.001),
loss='binary_crossentropy',
metrics = ['acc'])
Data Preprocessing
Let’s set up data generators that will read pictures in our source folders, convert them to float32 tensors, and feed them (with their labels) to our network. We’ll have one generator for the training images and one for the validation images. Our generators will yield batches of 20 images of size 150x150 and their labels (binary).
As you may already know, data that goes into neural networks should usually be normalized in some way to make it more amenable to processing by the network. (It is uncommon to feed raw pixels into a convnet.) In our case, we will preprocess our images by normalizing the pixel values to be in the [0, 1] range (originally all values are in the [0, 255] range).
In Keras this can be done via the keras.preprocessing.image.ImageDataGenerator class using the rescale parameter. This ImageDataGenerator class allows you to instantiate generators of augmented image batches (and their labels) via .flow(data, labels) or .flow_from_directory(directory). These generators can then be used with the Keras model methods that accept data generators as inputs: fit, evaluate_generator, and predict_generator.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# All images will be rescaled by 1./255.
train_datagen = ImageDataGenerator( rescale = 1.0/255. )
test_datagen = ImageDataGenerator( rescale = 1.0/255. )
# --------------------
# Flow training images in batches of 20 using train_datagen generator
# --------------------
train_generator = train_datagen.flow_from_directory(train_dir,
batch_size=20,
class_mode='binary',
target_size=(150, 150))
# --------------------
# Flow validation images in batches of 20 using test_datagen generator
# --------------------
validation_generator = test_datagen.flow_from_directory(validation_dir,
batch_size=20,
class_mode = 'binary',
target_size = (150, 150))
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Training
Let’s train on all 2,000 images available, for 15 epochs, and validate on all 1,000 test images. (This may take a few minutes to run.)
Do note the values per epoch. You’ll see 4 metrics – loss, accuracy, validation loss and validation accuracy.
The loss and accuracy are a great indication of progress of training. It’s making a guess as to the classification of the training data, and then measuring it against the known label, calculating the result. Accuracy is the portion of correct guesses. The validation accuracy is the measurement with the data that has not been used in training. As expected this would be a bit lower. You’ll learn about why this occurs in the section on overfitting later in this course. You are also given a callback function to stop the training when both the training and validation accuracy exceeds 70 percent.
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('acc')>0.7 and logs.get('val_acc')>0.7):
print("\nReached 99.8% accuracy so cancelling training!")
self.model.stop_training = True
callbacks = myCallback()
history = model.fit(
train_generator,
validation_data=validation_generator,
steps_per_epoch=100,
epochs=15,
callbacks=[callbacks],
validation_steps=50,
verbose=2
)
Epoch 1/15
100/100 - 73s - loss: 0.7992 - acc: 0.5460 - val_loss: 0.6597 - val_acc: 0.6240
Epoch 2/15
100/100 - 63s - loss: 0.6471 - acc: 0.6515 - val_loss: 0.5860 - val_acc: 0.6910
Epoch 3/15
Reached 99.8% accuracy so cancelling training!
100/100 - 63s - loss: 0.5551 - acc: 0.7100 - val_loss: 0.5867 - val_acc: 0.7070
Evaluating Accuracy and Loss for the Model
Let’s plot the training/validation accuracy and loss as collected during training:
#-----------------------------------------------------------
# Retrieve a list of list results on training and test data
# sets for each training epoch
#-----------------------------------------------------------
acc = history.history[ 'acc' ]
val_acc = history.history[ 'val_acc' ]
loss = history.history[ 'loss' ]
val_loss = history.history['val_loss' ]
epochs = range(len(acc)) # Get number of epochs
#------------------------------------------------
# Plot training and validation accuracy per epoch
#------------------------------------------------
plt.plot ( epochs, acc, label='Training')
plt.plot ( epochs, val_acc, label='Validation')
plt.title ('Training and validation accuracy')
plt.legend()
plt.figure()
#------------------------------------------------
# Plot training and validation loss per epoch
#------------------------------------------------
plt.plot ( epochs, loss, label='Training')
plt.plot ( epochs, val_loss, label='Validation')
plt.legend()
plt.title ('Training and validation loss')
Text(0.5, 1.0, 'Training and validation loss')
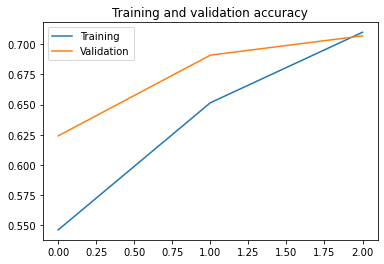
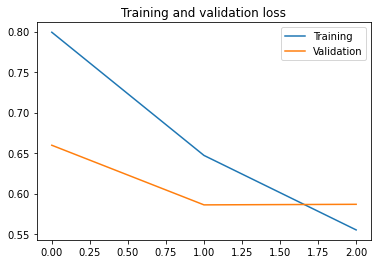
As you can see, we are overfitting like it’s getting out of fashion. Our training accuracy (in blue) gets close to 100% (!) while our validation accuracy (in orange) stalls as 70%. Our validation loss reaches its minimum after only five epochs.
Since we have a relatively small number of training examples (2000), overfitting should be our number one concern. Overfitting happens when a model exposed to too few examples learns patterns that do not generalize to new data, i.e. when the model starts using irrelevant features for making predictions. For instance, if you, as a human, only see three images of people who are lumberjacks, and three images of people who are sailors, and among them the only person wearing a cap is a lumberjack, you might start thinking that wearing a cap is a sign of being a lumberjack as opposed to a sailor. You would then make a pretty lousy lumberjack/sailor classifier.
Overfitting is the central problem in machine learning: given that we are fitting the parameters of our model to a given dataset, how can we make sure that the representations learned by the model will be applicable to data never seen before? How do we avoid learning things that are specific to the training data?
In the next exercise, we’ll look at ways to prevent overfitting in the cat vs. dog classification model.
Save the Model
In the cell below, save the trained model as a Keras model (.h5 file).
HINT: Use model.save(). Feel free to take a look at the Linear-to-JavaScript.ipynb example.
# EXERCISE: Save the trained model as a Keras HDF5 file.
saved_model_path = "./my_model.h5"
model.save(saved_model_path)
Run the TensorFlow.js Converter on The Saved Keras Model
In the cell below, use the tensorflowjs_converter to convert the saved Keras model into JSON format.
HINT: Make sure you specify the format of the input model as Keras by using the --input_format option. Feel free to take a look at the Linear-to-JavaScript.ipynb example and the TensorFlow.js converter documentation. There’s also an extra commented line below in case you need to re-run the converter and want to delete previously generated files.
# EXERCISE: Use the tensorflow.js converter to convert the saved Keras model into JSON format.
# Uncomment the next line if you want to clear previously generated .bin and json files before running the converter
# !rm *.bin model.json submission.zip
!tensorflowjs_converter --input_format=keras {saved_model_path} ./
If you did things correctly, you should now have a JSON file named model.json and various .bin files, such as group1-shard1of10.bin. The number of .bin files will depend on the size of your model: the larger your model, the greater the number of .bin files. The model.json file contains the architecture of your model and the .bin files will contain the weights of your model.
You can use the next line to zip all the necessary files for the grader. After running this, click Lab Files on the upper right of this Coursera Labs environment, click on /home/jovyan/work, then find submission.zip. You can then click on the checkbox beside it, then click Download at the top to save it locally. You’ll then upload this to the grader in the next classroom item.
# compress necessary files for grading
!zip submission.zip *.bin model.json
adding: group1-shard10of10.bin (deflated 8%)
adding: group1-shard1of10.bin (deflated 8%)
adding: group1-shard2of10.bin (deflated 8%)
adding: group1-shard3of10.bin (deflated 8%)
adding: group1-shard4of10.bin (deflated 8%)
adding: group1-shard5of10.bin (deflated 8%)
adding: group1-shard6of10.bin (deflated 8%)
adding: group1-shard7of10.bin (deflated 8%)
adding: group1-shard8of10.bin (deflated 8%)
adding: group1-shard9of10.bin (deflated 8%)
adding: model.json (deflated 82%)