Superhero (and Supervillain) Name Generator
Superhero Names Dataset
Task 2
- Import the data
- Create a tokenizer
- Char to index and Index to char dictionaries
!git clone https://github.com/am1tyadav/superhero
fatal: destination path 'superhero' already exists and is not an empty directory.
with open('superhero/superheroes.txt', 'r+') as f:
data = f.read()
data[:100]
'jumpa\t\ndoctor fate\t\nstarlight\t\nisildur\t\nlasher\t\nvarvara\t\nthe target\t\naxel\t\nbattra\t\nchangeling\t\npyrrh'
import tensorflow as tf
print(tf.__version__)
2.8.2
tokenizer = tf.keras.preprocessing.text.Tokenizer(
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~',
split='\n',
)
tokenizer.fit_on_texts(data)
char_to_index = tokenizer.word_index
index_to_char = dict((v, k) for k, v in char_to_index.items())
print(index_to_char)
{1: '\t', 2: 'a', 3: 'e', 4: 'r', 5: 'o', 6: 'n', 7: 'i', 8: ' ', 9: 't', 10: 's', 11: 'l', 12: 'm', 13: 'h', 14: 'd', 15: 'c', 16: 'u', 17: 'g', 18: 'k', 19: 'b', 20: 'p', 21: 'y', 22: 'w', 23: 'f', 24: 'v', 25: 'j', 26: 'z', 27: 'x', 28: 'q'}
Task 3
- Converting between names and sequences
names = data.splitlines()
names[:10]
['jumpa\t',
'doctor fate\t',
'starlight\t',
'isildur\t',
'lasher\t',
'varvara\t',
'the target\t',
'axel\t',
'battra\t',
'changeling\t']
tokenizer.texts_to_sequences(names[0])
[[25], [16], [12], [20], [2], [1]]
def name_to_seq(name):
return [tokenizer.texts_to_sequences(c)[0][0] for c in name]
[25, 16, 12, 20, 2, 1]
def seq_to_name(seq):
return ''.join([index_to_char[i] for i in seq if i != 0])
seq_to_name(name_to_seq(names[0]))
'jumpa\t'
Task 4
- Creating sequences
- Padding all sequences
sequences = []
for name in names:
seq = name_to_seq(name)
if len(seq) >= 2:
sequences += [seq[:i] for i in range(2, len(seq) + 1)]
[[25, 16],
[25, 16, 12],
[25, 16, 12, 20],
[25, 16, 12, 20, 2],
[25, 16, 12, 20, 2, 1],
[14, 5],
[14, 5, 15],
[14, 5, 15, 9],
[14, 5, 15, 9, 5],
[14, 5, 15, 9, 5, 4]]
max_len = max([len(x) for x in sequences])
print(max_len)
33
padded_sequences = tf.keras.preprocessing.sequence.pad_sequences(
sequences = sequences,
padding = 'pre',
maxlen = max_len
)
print(padded_sequences[0])
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 25 16]
(88279, 33)
Task 5: Creating Training and Validation Sets
- Creating training and validation sets
x, y = padded_sequences[:, :-1], padded_sequences[:, -1]
print(x.shape, y.shape)
(88279, 32) (88279,)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state = 42)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
(66209, 32) (66209,)
(22070, 32) (22070,)
num_chars = len(char_to_index.keys()) + 1
print(num_chars)
29
Task 6: Creating the Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Conv1D, MaxPool1D, LSTM
from tensorflow.keras.layers import Bidirectional, Dense
model = Sequential([
Embedding(num_chars, 8, input_length = max_len - 1),
Conv1D(64, 5, strides = 1, activation = 'tanh', padding = 'causal'),
MaxPool1D(2),
LSTM(32),
Dense(num_chars, activation = 'softmax'),
])
model.compile(
loss = 'sparse_categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy']
)
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 32, 8) 232
conv1d (Conv1D) (None, 32, 64) 2624
max_pooling1d (MaxPooling1D (None, 16, 64) 0
)
lstm (LSTM) (None, 32) 12416
dense (Dense) (None, 29) 957
=================================================================
Total params: 16,229
Trainable params: 16,229
Non-trainable params: 0
_________________________________________________________________
Task 7: Training the Model
h = model.fit(
x_train, y_train,
validation_data = (x_test, y_test),
epochs = 50, verbose = 1,
callbacks = [
tf.keras.callbacks.EarlyStopping(monitor = 'val_accuracy', patience = 3)
]
)
Epoch 1/50
2070/2070 [==============================] - 18s 7ms/step - loss: 2.7422 - accuracy: 0.1916 - val_loss: 2.5601 - val_accuracy: 0.2252
Epoch 2/50
2070/2070 [==============================] - 13s 6ms/step - loss: 2.5316 - accuracy: 0.2389 - val_loss: 2.4799 - val_accuracy: 0.2497
Epoch 3/50
2070/2070 [==============================] - 13s 6ms/step - loss: 2.4649 - accuracy: 0.2576 - val_loss: 2.4416 - val_accuracy: 0.2690
Epoch 4/50
2070/2070 [==============================] - 13s 6ms/step - loss: 2.4177 - accuracy: 0.2699 - val_loss: 2.4021 - val_accuracy: 0.2774
Epoch 5/50
2070/2070 [==============================] - 15s 7ms/step - loss: 2.3762 - accuracy: 0.2828 - val_loss: 2.3650 - val_accuracy: 0.2895
Epoch 6/50
2070/2070 [==============================] - 12s 6ms/step - loss: 2.3414 - accuracy: 0.2940 - val_loss: 2.3394 - val_accuracy: 0.2939
Epoch 7/50
2070/2070 [==============================] - 13s 6ms/step - loss: 2.3117 - accuracy: 0.3004 - val_loss: 2.3205 - val_accuracy: 0.2997
Epoch 8/50
2070/2070 [==============================] - 12s 6ms/step - loss: 2.2848 - accuracy: 0.3096 - val_loss: 2.3010 - val_accuracy: 0.3066
Epoch 9/50
2070/2070 [==============================] - 13s 6ms/step - loss: 2.2613 - accuracy: 0.3169 - val_loss: 2.2872 - val_accuracy: 0.3075
Epoch 10/50
2070/2070 [==============================] - 12s 6ms/step - loss: 2.2401 - accuracy: 0.3243 - val_loss: 2.2709 - val_accuracy: 0.3138
Epoch 11/50
2070/2070 [==============================] - 13s 6ms/step - loss: 2.2193 - accuracy: 0.3313 - val_loss: 2.2592 - val_accuracy: 0.3180
Epoch 12/50
2070/2070 [==============================] - 13s 6ms/step - loss: 2.1999 - accuracy: 0.3349 - val_loss: 2.2469 - val_accuracy: 0.3235
Epoch 13/50
2070/2070 [==============================] - 13s 6ms/step - loss: 2.1818 - accuracy: 0.3424 - val_loss: 2.2392 - val_accuracy: 0.3258
Epoch 14/50
2070/2070 [==============================] - 13s 6ms/step - loss: 2.1658 - accuracy: 0.3463 - val_loss: 2.2323 - val_accuracy: 0.3254
Epoch 15/50
2070/2070 [==============================] - 13s 6ms/step - loss: 2.1508 - accuracy: 0.3527 - val_loss: 2.2232 - val_accuracy: 0.3346
Epoch 16/50
2070/2070 [==============================] - 12s 6ms/step - loss: 2.1352 - accuracy: 0.3574 - val_loss: 2.2152 - val_accuracy: 0.3350
Epoch 17/50
2070/2070 [==============================] - 13s 6ms/step - loss: 2.1221 - accuracy: 0.3618 - val_loss: 2.2120 - val_accuracy: 0.3382
Epoch 18/50
2070/2070 [==============================] - 13s 6ms/step - loss: 2.1088 - accuracy: 0.3657 - val_loss: 2.2012 - val_accuracy: 0.3446
Epoch 19/50
2070/2070 [==============================] - 12s 6ms/step - loss: 2.0968 - accuracy: 0.3706 - val_loss: 2.2021 - val_accuracy: 0.3429
Epoch 20/50
2070/2070 [==============================] - 12s 6ms/step - loss: 2.0853 - accuracy: 0.3740 - val_loss: 2.2012 - val_accuracy: 0.3439
Epoch 21/50
2070/2070 [==============================] - 13s 6ms/step - loss: 2.0742 - accuracy: 0.3788 - val_loss: 2.1938 - val_accuracy: 0.3433
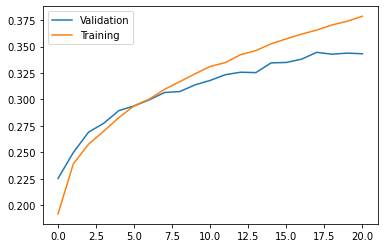
import matplotlib.pyplot as plt
epochs_ran = len(h.history['loss'])
plt.plot(range(0, epochs_ran), h.history['val_accuracy'], label = 'Validation')
plt.plot(range(0, epochs_ran), h.history['accuracy'], label = 'Training')
plt.legend()
plt.show()
Task 8: Generate Names!
def generate_names(seed):
for i in range(0, 40):
seq = name_to_seq(seed)
padded = tf.keras.preprocessing.sequence.pad_sequences(
[seq],
padding = 'pre',
maxlen = max_len - 1,
truncating = 'pre',
)
pred = model.predict(padded)[0]
pred_char = index_to_char[tf.argmax(pred).numpy()]
seed += pred_char
if pred_char == '\t':
break
print(seed)
aren the stark
binder strange
quantiin man
olessa maran