Coursera
Feature transformation with Amazon SageMaker processing job and Feature Store
Introduction
In this lab you will start with the raw Women’s Clothing Reviews dataset and prepare it to train a BERT-based natural language processing (NLP) model. The model will be used to classify customer reviews into positive (1), neutral (0) and negative (-1) sentiment.
You will convert the original review text into machine-readable features used by BERT. To perform the required feature transformation you will configure an Amazon SageMaker processing job, which will be running a custom Python script.
Table of Contents
# please ignore warning messages during the installation
!pip install --disable-pip-version-check -q sagemaker==2.35.0
!conda install -q -y pytorch==1.6.0 -c pytorch
!pip install --disable-pip-version-check -q transformers==3.5.1
!pip install -q protobuf==3.20.*
[33mDEPRECATION: pyodbc 4.0.0-unsupported has a non-standard version number. pip 23.3 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pyodbc or contact the author to suggest that they release a version with a conforming version number. Discussion can be found at https://github.com/pypa/pip/issues/12063[0m[33m
[0m[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
sparkmagic 0.20.4 requires nest-asyncio==1.5.5, but you have nest-asyncio 1.5.8 which is incompatible.[0m[31m
[0m[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0mCollecting package metadata (current_repodata.json): ...working... done
Solving environment: ...working... failed with initial frozen solve. Retrying with flexible solve.
Collecting package metadata (repodata.json): ...working... done
Solving environment: ...working...
The environment is inconsistent, please check the package plan carefully
The following packages are causing the inconsistency:
- defaults/linux-64::anaconda-client==1.7.2=py37_0
- defaults/noarch::anaconda-project==0.8.4=py_0
- defaults/linux-64::bokeh==1.4.0=py37_0
- defaults/noarch::dask==2.11.0=py_0
- defaults/linux-64::distributed==2.11.0=py37_0
- defaults/linux-64::spyder==4.0.1=py37_0
- defaults/linux-64::watchdog==0.10.2=py37_0
done
## Package Plan ##
environment location: /opt/conda
added / updated specs:
- pytorch==1.6.0
The following packages will be downloaded:
package | build
---------------------------|-----------------
ca-certificates-2023.08.22 | h06a4308_0 123 KB
cudatoolkit-10.2.89 | hfd86e86_1 365.1 MB
ninja-1.10.2 | h06a4308_5 8 KB
ninja-base-1.10.2 | hd09550d_5 109 KB
openssl-1.1.1w | h7f8727e_0 3.7 MB
pytorch-1.6.0 |py3.7_cuda10.2.89_cudnn7.6.5_0 537.7 MB pytorch
pyyaml-5.3.1 | py37h7b6447c_0 181 KB
------------------------------------------------------------
Total: 906.9 MB
The following NEW packages will be INSTALLED:
cudatoolkit pkgs/main/linux-64::cudatoolkit-10.2.89-hfd86e86_1 None
ninja pkgs/main/linux-64::ninja-1.10.2-h06a4308_5 None
ninja-base pkgs/main/linux-64::ninja-base-1.10.2-hd09550d_5 None
pytorch pytorch/linux-64::pytorch-1.6.0-py3.7_cuda10.2.89_cudnn7.6.5_0 None
pyyaml pkgs/main/linux-64::pyyaml-5.3.1-py37h7b6447c_0 None
The following packages will be UPDATED:
ca-certificates conda-forge::ca-certificates-2023.7.2~ --> pkgs/main::ca-certificates-2023.08.22-h06a4308_0 None
openssl conda-forge::openssl-1.1.1l-h7f98852_0 --> pkgs/main::openssl-1.1.1w-h7f8727e_0 None
Preparing transaction: ...working... done
Verifying transaction: ...working... done
Executing transaction: ...working... done
Retrieving notices: ...working... done
[33mDEPRECATION: pyodbc 4.0.0-unsupported has a non-standard version number. pip 23.3 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pyodbc or contact the author to suggest that they release a version with a conforming version number. Discussion can be found at https://github.com/pypa/pip/issues/12063[0m[33m
[0m[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0m[33mDEPRECATION: pyodbc 4.0.0-unsupported has a non-standard version number. pip 23.3 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pyodbc or contact the author to suggest that they release a version with a conforming version number. Discussion can be found at https://github.com/pypa/pip/issues/12063[0m[33m
[0m[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip is available: [0m[31;49m23.2.1[0m[39;49m -> [0m[32;49m23.3.1[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m
import boto3
import sagemaker
import botocore
config = botocore.config.Config(user_agent_extra='dlai-pds/c2/w1')
# low-level service client of the boto3 session
sm = boto3.client(service_name='sagemaker',
config=config)
featurestore_runtime = boto3.client(service_name='sagemaker-featurestore-runtime',
config=config)
sess = sagemaker.Session(sagemaker_client=sm,
sagemaker_featurestore_runtime_client=featurestore_runtime)
bucket = sess.default_bucket()
role = sagemaker.get_execution_role()
region = sess.boto_region_name
/opt/conda/lib/python3.7/site-packages/boto3/compat.py:82: PythonDeprecationWarning: Boto3 will no longer support Python 3.7 starting December 13, 2023. To continue receiving service updates, bug fixes, and security updates please upgrade to Python 3.8 or later. More information can be found here: https://aws.amazon.com/blogs/developer/python-support-policy-updates-for-aws-sdks-and-tools/
warnings.warn(warning, PythonDeprecationWarning)
1. Configure the SageMaker Feature Store
1.1. Configure dataset
The raw dataset is in the public S3 bucket. Let’s start by specifying the S3 location of it:
raw_input_data_s3_uri = 's3://dlai-practical-data-science/data/raw/'
print(raw_input_data_s3_uri)
s3://dlai-practical-data-science/data/raw/
List the files in the S3 bucket (in this case it will be just one file):
!aws s3 ls $raw_input_data_s3_uri
2021-04-30 02:21:06 8457214 womens_clothing_ecommerce_reviews.csv
1.2. Configure the SageMaker feature store
As the result of the transformation, in addition to generating files in S3 bucket, you will also save the transformed data in the Amazon SageMaker Feature Store to be used by others in your organization, for example.
To configure a Feature Store you need to setup a Feature Group. This is the main resource containing all of the metadata related to the data stored in the Feature Store. A Feature Group should contain a list of Feature Definitions. A Feature Definition consists of a name and the data type. The Feature Group also contains an online store configuration and an offline store configuration controlling where the data is stored. Enabling the online store allows quick access to the latest value for a record via the GetRecord API. The offline store allows storage of the data in your S3 bucket. You will be using the offline store in this lab.
Let’s setup the Feature Group name and the Feature Store offline prefix in S3 bucket (you will use those later in the lab):
import time
timestamp = int(time.time())
feature_group_name = 'reviews-feature-group-' + str(timestamp)
feature_store_offline_prefix = 'reviews-feature-store-' + str(timestamp)
print('Feature group name: {}'.format(feature_group_name))
print('Feature store offline prefix in S3: {}'.format(feature_store_offline_prefix))
Feature group name: reviews-feature-group-1697991113
Feature store offline prefix in S3: reviews-feature-store-1697991113
Taking two features from the original raw dataset (Review Text and Rating), you will transform it preparing to be used for the model training and then to be saved in the Feature Store. Here you will define the related features to be stored as a list of FeatureDefinition.
from sagemaker.feature_store.feature_definition import (
FeatureDefinition,
FeatureTypeEnum,
)
feature_definitions = [
# unique ID of the review
FeatureDefinition(feature_name='review_id', feature_type=FeatureTypeEnum.STRING),
# ingestion timestamp
FeatureDefinition(feature_name='date', feature_type=FeatureTypeEnum.STRING),
# sentiment: -1 (negative), 0 (neutral) or 1 (positive). It will be found the Rating values (1, 2, 3, 4, 5)
FeatureDefinition(feature_name='sentiment', feature_type=FeatureTypeEnum.STRING),
# label ID of the target class (sentiment)
FeatureDefinition(feature_name='label_id', feature_type=FeatureTypeEnum.STRING),
# reviews encoded with the BERT tokenizer
FeatureDefinition(feature_name='input_ids', feature_type=FeatureTypeEnum.STRING),
# original Review Text
FeatureDefinition(feature_name='review_body', feature_type=FeatureTypeEnum.STRING),
# train/validation/test label
FeatureDefinition(feature_name='split_type', feature_type=FeatureTypeEnum.STRING)
]
Exercise 1
Create the feature group using the feature definitions defined above.
Instructions: Use the FeatureGroup function passing the defined above feature group name and the feature definitions.
feature_group = FeatureGroup(
name=..., # Feature Group name
feature_definitions=..., # a list of Feature Definitions
sagemaker_session=sess # SageMaker session
)
from sagemaker.feature_store.feature_group import FeatureGroup
feature_group = FeatureGroup(
### BEGIN SOLUTION - DO NOT delete this comment for grading purposes
name=feature_group_name,
feature_definitions=feature_definitions,
### END SOLUTION - DO NOT delete this comment for grading purposes
sagemaker_session=sess
)
print(feature_group)
FeatureGroup(name='reviews-feature-group-1697991113', sagemaker_session=<sagemaker.session.Session object at 0x7fb0c34fe390>, feature_definitions=[FeatureDefinition(feature_name='review_id', feature_type=<FeatureTypeEnum.STRING: 'String'>), FeatureDefinition(feature_name='date', feature_type=<FeatureTypeEnum.STRING: 'String'>), FeatureDefinition(feature_name='sentiment', feature_type=<FeatureTypeEnum.STRING: 'String'>), FeatureDefinition(feature_name='label_id', feature_type=<FeatureTypeEnum.STRING: 'String'>), FeatureDefinition(feature_name='input_ids', feature_type=<FeatureTypeEnum.STRING: 'String'>), FeatureDefinition(feature_name='review_body', feature_type=<FeatureTypeEnum.STRING: 'String'>), FeatureDefinition(feature_name='split_type', feature_type=<FeatureTypeEnum.STRING: 'String'>)])
You will use the defined Feature Group later in this lab, the actual creation of the Feature Group will take place in the processing job. Now let’s move into the setup of the processing job to transform the dataset.
2. Transform the dataset
You will configure a SageMaker processing job to run a custom Python script to balance and transform the raw data into a format used by BERT model.
Set the transformation parameters including the instance type, instance count, and train/validation/test split percentages. For the purposes of this lab, you will use a relatively small instance type. Please refer to this link for additional instance types that may work for your use case outside of this lab.
You can also choose whether you want to balance the dataset or not. In this case, you will balance the dataset to avoid class imbalance in the target variable, sentiment.
Another important parameter of the model is the max_seq_length, which specifies the maximum length of the classified reviews for the RoBERTa model. If the sentence is shorter than the maximum length parameter, it will be padded. In another case, when the sentence is longer, it will be truncated from the right side.
Since a smaller max_seq_length leads to faster training and lower resource utilization, you want to find the smallest power-of-2 that captures 100% of our reviews. For this dataset, the 100th percentile is 115. However, it’s best to stick with powers-of-2 when using BERT. So let’s choose 128 as this is the smallest power-of-2 greater than 115. You will see below how the shorter sentences will be padded to a maximum length.
mean 52.512374
std 31.387048
min 1.000000
10% 10.000000
20% 22.000000
30% 32.000000
40% 41.000000
50% 51.000000
60% 61.000000
70% 73.000000
80% 88.000000
90% 97.000000
100% 115.000000
max 115.000000

processing_instance_type='ml.c5.xlarge'
processing_instance_count=1
train_split_percentage=0.90
validation_split_percentage=0.05
test_split_percentage=0.05
balance_dataset=True
max_seq_length=128
To balance and transform our data, you will use a scikit-learn-based processing job. This is essentially a generic Python processing job with scikit-learn pre-installed. You can specify the version of scikit-learn you wish to use. Also pass the SageMaker execution role, processing instance type and instance count.
from sagemaker.sklearn.processing import SKLearnProcessor
processor = SKLearnProcessor(
framework_version='0.23-1',
role=role,
instance_type=processing_instance_type,
instance_count=processing_instance_count,
env={'AWS_DEFAULT_REGION': region},
max_runtime_in_seconds=7200
)
The processing job will be running the Python code from the file src/prepare_data.py. In the following exercise you will review the contents of the file and familiarize yourself with main parts of it.
Exercise 2
- Open the file src/prepare_data.py. Go through the comments to understand its content.
- Find and review the
convert_to_bert_input_ids()function, which contains the RoBERTatokenizerconfiguration. - Complete method
encode_plusof the RoBERTatokenizer. Pass themax_seq_lengthas a value for the argumentmax_length. It defines a pad to a maximum length specified. - Save the file src/prepare_data.py (with the menu command File -> Save Python File).
This cell will take approximately 1-2 minutes to run.
import sys, importlib
sys.path.append('src/')
# import the `prepare_data.py` module
import prepare_data
# reload the module if it has been previously loaded
if 'prepare_data' in sys.modules:
importlib.reload(prepare_data)
input_ids = prepare_data.convert_to_bert_input_ids("this product is great!", max_seq_length)
updated_correctly = False
if len(input_ids) != max_seq_length:
print('#######################################################################################################')
print('Please check that the function \'convert_to_bert_input_ids\' in the file src/prepare_data.py is complete.')
print('#######################################################################################################')
raise Exception('Please check that the function \'convert_to_bert_input_ids\' in the file src/prepare_data.py is complete.')
else:
print('##################')
print('Updated correctly!')
print('##################')
updated_correctly = True
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=898823.0, style=ProgressStyle(descripti…
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=456318.0, style=ProgressStyle(descripti…
##################
Updated correctly!
##################
Review the results of tokenization for the given example ("this product is great!"):
input_ids = prepare_data.convert_to_bert_input_ids("this product is great!", max_seq_length)
print(input_ids)
print('Length of the sequence: {}'.format(len(input_ids)))
[0, 9226, 1152, 16, 372, 328, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
Length of the sequence: 128
Launch the processing job with the custom script passing defined above parameters.
from sagemaker.processing import ProcessingInput, ProcessingOutput
if (updated_correctly):
processor.run(code='src/prepare_data.py',
inputs=[
ProcessingInput(source=raw_input_data_s3_uri,
destination='/opt/ml/processing/input/data/',
s3_data_distribution_type='ShardedByS3Key')
],
outputs=[
ProcessingOutput(output_name='sentiment-train',
source='/opt/ml/processing/output/sentiment/train',
s3_upload_mode='EndOfJob'),
ProcessingOutput(output_name='sentiment-validation',
source='/opt/ml/processing/output/sentiment/validation',
s3_upload_mode='EndOfJob'),
ProcessingOutput(output_name='sentiment-test',
source='/opt/ml/processing/output/sentiment/test',
s3_upload_mode='EndOfJob')
],
arguments=['--train-split-percentage', str(train_split_percentage),
'--validation-split-percentage', str(validation_split_percentage),
'--test-split-percentage', str(test_split_percentage),
'--balance-dataset', str(balance_dataset),
'--max-seq-length', str(max_seq_length),
'--feature-store-offline-prefix', str(feature_store_offline_prefix),
'--feature-group-name', str(feature_group_name)
],
logs=True,
wait=False)
else:
print('#######################################')
print('Please update the code correctly above.')
print('#######################################')
Job Name: sagemaker-scikit-learn-2023-10-22-16-13-41-140
Inputs: [{'InputName': 'input-1', 'AppManaged': False, 'S3Input': {'S3Uri': 's3://dlai-practical-data-science/data/raw/', 'LocalPath': '/opt/ml/processing/input/data/', 'S3DataType': 'S3Prefix', 'S3InputMode': 'File', 'S3DataDistributionType': 'ShardedByS3Key', 'S3CompressionType': 'None'}}, {'InputName': 'code', 'AppManaged': False, 'S3Input': {'S3Uri': 's3://sagemaker-us-east-1-062287423314/sagemaker-scikit-learn-2023-10-22-16-13-41-140/input/code/prepare_data.py', 'LocalPath': '/opt/ml/processing/input/code', 'S3DataType': 'S3Prefix', 'S3InputMode': 'File', 'S3DataDistributionType': 'FullyReplicated', 'S3CompressionType': 'None'}}]
Outputs: [{'OutputName': 'sentiment-train', 'AppManaged': False, 'S3Output': {'S3Uri': 's3://sagemaker-us-east-1-062287423314/sagemaker-scikit-learn-2023-10-22-16-13-41-140/output/sentiment-train', 'LocalPath': '/opt/ml/processing/output/sentiment/train', 'S3UploadMode': 'EndOfJob'}}, {'OutputName': 'sentiment-validation', 'AppManaged': False, 'S3Output': {'S3Uri': 's3://sagemaker-us-east-1-062287423314/sagemaker-scikit-learn-2023-10-22-16-13-41-140/output/sentiment-validation', 'LocalPath': '/opt/ml/processing/output/sentiment/validation', 'S3UploadMode': 'EndOfJob'}}, {'OutputName': 'sentiment-test', 'AppManaged': False, 'S3Output': {'S3Uri': 's3://sagemaker-us-east-1-062287423314/sagemaker-scikit-learn-2023-10-22-16-13-41-140/output/sentiment-test', 'LocalPath': '/opt/ml/processing/output/sentiment/test', 'S3UploadMode': 'EndOfJob'}}]
You can see the information about the processing jobs using the describe function. The result is in dictionary format. Let’s pull the processing job name:
scikit_processing_job_name = processor.jobs[-1].describe()['ProcessingJobName']
print('Processing job name: {}'.format(scikit_processing_job_name))
Processing job name: sagemaker-scikit-learn-2023-10-22-16-13-41-140
Exercise 3
Pull the processing job status from the processing job description.
Instructions: Print the keys of the processing job description dictionary, choose the one related to the status of the processing job and print the value of it.
print(processor.jobs[-1].describe().keys())
dict_keys(['ProcessingInputs', 'ProcessingOutputConfig', 'ProcessingJobName', 'ProcessingResources', 'StoppingCondition', 'AppSpecification', 'Environment', 'RoleArn', 'ProcessingJobArn', 'ProcessingJobStatus', 'LastModifiedTime', 'CreationTime', 'ResponseMetadata'])
### BEGIN SOLUTION - DO NOT delete this comment for grading purposes
scikit_processing_job_status = processor.jobs[-1].describe()["ProcessingJobStatus"]
### END SOLUTION - DO NOT delete this comment for grading purposes
print('Processing job status: {}'.format(scikit_processing_job_status))
Processing job status: InProgress
Review the created processing job in the AWS console.
Instructions:
- open the link
- notice that you are in the section
Amazon SageMaker->Processing jobs - check the name of the processing job, its status and other available information
from IPython.core.display import display, HTML
display(HTML('<b>Review <a target="blank" href="https://console.aws.amazon.com/sagemaker/home?region={}#/processing-jobs/{}">processing job</a></b>'.format(region, scikit_processing_job_name)))
Review processing job
Wait for about 5 minutes to review the CloudWatch Logs. You may open the file src/prepare_data.py again and examine the outputs of the code in the CloudWatch logs.
from IPython.core.display import display, HTML
display(HTML('<b>Review <a target="blank" href="https://console.aws.amazon.com/cloudwatch/home?region={}#logStream:group=/aws/sagemaker/ProcessingJobs;prefix={};streamFilter=typeLogStreamPrefix">CloudWatch logs</a> after about 5 minutes</b>'.format(region, scikit_processing_job_name)))
Review CloudWatch logs after about 5 minutes
After the completion of the processing job you can also review the output in the S3 bucket.
from IPython.core.display import display, HTML
display(HTML('<b>Review <a target="blank" href="https://s3.console.aws.amazon.com/s3/buckets/{}/{}/?region={}&tab=overview">S3 output data</a> after the processing job has completed</b>'.format(bucket, scikit_processing_job_name, region)))
Review S3 output data after the processing job has completed
Wait for the processing job to complete.
This cell will take approximately 15 minutes to run.
%%time
running_processor = sagemaker.processing.ProcessingJob.from_processing_name(
processing_job_name=scikit_processing_job_name,
sagemaker_session=sess
)
running_processor.wait(logs=False)
!CPU times: user 19 ms, sys: 386 µs, total: 19.4 ms
Wall time: 157 ms
Please wait until ^^ Processing Job ^^ completes above
Inspect the transformed and balanced data in the S3 bucket.
processing_job_description = running_processor.describe()
output_config = processing_job_description['ProcessingOutputConfig']
for output in output_config['Outputs']:
if output['OutputName'] == 'sentiment-train':
processed_train_data_s3_uri = output['S3Output']['S3Uri']
if output['OutputName'] == 'sentiment-validation':
processed_validation_data_s3_uri = output['S3Output']['S3Uri']
if output['OutputName'] == 'sentiment-test':
processed_test_data_s3_uri = output['S3Output']['S3Uri']
print(processed_train_data_s3_uri)
print(processed_validation_data_s3_uri)
print(processed_test_data_s3_uri)
s3://sagemaker-us-east-1-062287423314/sagemaker-scikit-learn-2023-10-22-16-13-41-140/output/sentiment-train
s3://sagemaker-us-east-1-062287423314/sagemaker-scikit-learn-2023-10-22-16-13-41-140/output/sentiment-validation
s3://sagemaker-us-east-1-062287423314/sagemaker-scikit-learn-2023-10-22-16-13-41-140/output/sentiment-test
!aws s3 ls $processed_train_data_s3_uri/
2023-10-22 16:27:36 4891119 part-algo-1-womens_clothing_ecommerce_reviews.tsv
!aws s3 ls $processed_validation_data_s3_uri/
2023-10-22 16:27:36 270895 part-algo-1-womens_clothing_ecommerce_reviews.tsv
!aws s3 ls $processed_test_data_s3_uri/
2023-10-22 16:27:36 276431 part-algo-1-womens_clothing_ecommerce_reviews.tsv
Copy the data into the folder balanced.
!aws s3 cp $processed_train_data_s3_uri/part-algo-1-womens_clothing_ecommerce_reviews.tsv ./balanced/sentiment-train/
!aws s3 cp $processed_validation_data_s3_uri/part-algo-1-womens_clothing_ecommerce_reviews.tsv ./balanced/sentiment-validation/
!aws s3 cp $processed_test_data_s3_uri/part-algo-1-womens_clothing_ecommerce_reviews.tsv ./balanced/sentiment-test/
download: s3://sagemaker-us-east-1-062287423314/sagemaker-scikit-learn-2023-10-22-16-13-41-140/output/sentiment-train/part-algo-1-womens_clothing_ecommerce_reviews.tsv to balanced/sentiment-train/part-algo-1-womens_clothing_ecommerce_reviews.tsv
download: s3://sagemaker-us-east-1-062287423314/sagemaker-scikit-learn-2023-10-22-16-13-41-140/output/sentiment-validation/part-algo-1-womens_clothing_ecommerce_reviews.tsv to balanced/sentiment-validation/part-algo-1-womens_clothing_ecommerce_reviews.tsv
download: s3://sagemaker-us-east-1-062287423314/sagemaker-scikit-learn-2023-10-22-16-13-41-140/output/sentiment-test/part-algo-1-womens_clothing_ecommerce_reviews.tsv to balanced/sentiment-test/part-algo-1-womens_clothing_ecommerce_reviews.tsv
Review the training, validation and test data outputs:
!head -n 5 ./balanced/sentiment-train/part-algo-1-womens_clothing_ecommerce_reviews.tsv
review_id sentiment label_id input_ids review_body date
2861 0 1 [0, 4, 879, 45779, 24, 478, 23, 5, 35653, 233, 9, 127, 28097, 1437, 98, 24, 938, 75, 182, 34203, 4, 5, 477, 11, 5, 124, 21, 67, 761, 9, 8372, 1437, 8, 160, 1312, 4, 939, 56, 7, 671, 4, 1256, 3195, 1437, 600, 4, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] .unfortunately it hit at the widest part of my hips so it wasn't very flattering. the point in the back was also kind of odd and off center. i had to return. pretty color though. 2023-10-22T16:21:07Z
14062 1 2 [0, 23675, 3741, 2990, 3588, 4, 4187, 3989, 53, 16, 1256, 614, 11, 5, 748, 5397, 4, 939, 524, 11044, 219, 36, 3079, 16134, 43, 8, 240, 10, 22, 41935, 12, 658, 113, 11689, 7, 146, 5, 5397, 1902, 593, 4, 24, 18, 182, 1365, 7, 3568, 8, 2422, 3137, 24382, 4, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] "Little clack dress. classic shape but is pretty low in the v neck. i am busty (34dd) and need a ""push-up"" bra to make the neckline close. it's very easy to wear and super comfy." 2023-10-22T16:21:07Z
14266 0 1 [0, 100, 421, 7, 657, 42, 1437, 187, 939, 2333, 356, 205, 11, 42, 2496, 9, 8443, 4, 24, 18, 2299, 3473, 8, 5, 2564, 21, 2051, 1437, 53, 939, 269, 218, 75, 575, 13, 5, 11678, 14893, 8, 5, 1374, 356, 21, 95, 22, 1794, 298, 72, 24, 18, 164, 124, 1437, 9574, 4, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] "I expected to love this since i usually look good in this style of jacket. it's definitely comfortable and the fit was fine but i really don't care for the wooden buttons and the overall look was just ""meh."" it's going back unfortunately." 2023-10-22T16:21:07Z
4348 0 1 [0, 100, 216, 42, 16, 3518, 7, 28, 10, 7082, 1437, 3041, 219, 2564, 61, 16, 2230, 5, 2496, 939, 657, 4, 959, 1437, 42, 16, 1684, 10178, 12, 3341, 4, 939, 437, 843, 688, 5283, 8, 939, 64, 1153, 2564, 80, 9, 162, 11, 127, 2340, 1836, 650, 4, 10199, 16, 182, 7174, 8, 6184, 1326, 101, 12402, 873, 37103, 4, 1307, 741, 22539, 1437, 941, 71, 1782, 10, 367, 195, 12, 16823, 4, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] I know this is supposed to be a loose flowy fit which is exactly the style i love. however this is beyond tent-like. i'm 40 weeks pregnant and i can probably fit two of me in my normal size small. fabric is very thin and pattern looks like drab wallpaper. huge bummer especially after seeing a few 5-stars. 2023-10-22T16:21:07Z
!head -n 5 ./balanced/sentiment-validation/part-algo-1-womens_clothing_ecommerce_reviews.tsv
review_id sentiment label_id input_ids review_body date
7554 -1 0 [0, 713, 56, 10, 11962, 1521, 53, 41, 29747, 24203, 2564, 13, 162, 4, 1437, 24, 21, 2233, 219, 8, 156, 127, 39499, 356, 13868, 16572, 4, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] This had a cute design but an unflattering fit for me. it was boxy and made my boobs look droopy. 2023-10-22T16:21:07Z
13110 0 1 [0, 133, 1521, 16, 11962, 1437, 53, 89, 16, 169, 350, 203, 10199, 11, 5, 795, 233, 9, 5, 6399, 4, 67, 1437, 5, 10199, 13, 5, 795, 233, 3977, 783, 12349, 2773, 4, 3867, 47, 2324, 198, 41, 6440, 1437, 47, 189, 45, 236, 7, 3568, 24, 751, 5, 790, 4, 939, 1682, 5, 6399, 7, 3568, 198, 5, 790, 4, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] The design is cute but there is way too much fabric in the lower part of the shirt. also the fabric for the lower part crumples easily. unless you carry around an iron you may not want to wear it outside the house. i kept the shirt to wear around the house. 2023-10-22T16:21:07Z
13403 1 2 [0, 2387, 2674, 9304, 328, 51, 109, 422, 2829, 739, 98, 939, 23855, 159, 4, 939, 33, 155, 8089, 8, 40, 535, 7, 1606, 55, 328, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] My favorite pants! they do run slightly large so i sized down. i have 3 colors and will continue to add more! 2023-10-22T16:21:07Z
16500 -1 0 [0, 7199, 686, 54, 42, 16, 13, 53, 63, 45, 13, 162, 4, 16576, 21, 251, 1437, 13116, 8, 181, 33650, 15, 127, 28097, 4, 939, 115, 45, 120, 24, 7, 6105, 12461, 4, 2085, 47, 33, 7, 28, 231, 108, 7, 2999, 42, 160, 734, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] Not sure who this is for but its not for me. skirt was long stiff and puffy on my hips. i could not get it to lie correctly. maybe you have to be 6' to pull this off... 2023-10-22T16:21:07Z
!head -n 5 ./balanced/sentiment-test/part-algo-1-womens_clothing_ecommerce_reviews.tsv
review_id sentiment label_id input_ids review_body date
119 0 1 [0, 100, 657, 5, 24117, 8089, 9, 42, 299, 8, 11464, 939, 115, 3568, 24, 223, 10, 910, 3964, 4183, 8443, 8, 7922, 16576, 13, 173, 4, 18965, 642, 1437, 14, 18, 66, 5, 2931, 4, 42, 1521, 16, 2129, 4, 13, 65, 1437, 42, 16, 45, 10, 2125, 13, 10, 4716, 1459, 693, 19, 117, 28762, 8, 939, 218, 75, 216, 141, 1268, 19, 10, 1181, 28762, 15033, 326, 39, 4, 42, 2323, 1065, 127, 18951, 14084, 1054, 15, 8, 939, 300, 6256, 594, 1459, 132, 4, 939, 33, 117, 28762, 4, 98, 1437, 396, 10, 8443, 1437, 939, 74, 393, 3568, 42, 4, 24, 18, 182, 614, 847, 7586, 627, 124, 16, 182, 614, 7586, 405, 18, 10, 410, 7082, 53, 939, 422, 227, 10, 2] I love the metallic colors of this top and figured i could wear it under a ruched jacket and circle skirt for work. welp that's out the window. this design is poor. for one this is not a piece for a petite woman with no torso and i don't know how anyone with a longer torso wears t his. this hits above my belly botton on and i got apetite 2. i have no torso. so without a jacket i would never wear this. it's very low cut..the back is very low..it's a little loose but i run between a 2 and a 4. 2023-10-22T16:21:07Z
9328 1 2 [0, 100, 1381, 543, 7, 146, 42, 173, 142, 24, 16, 2721, 1437, 53, 1249, 62, 3357, 24, 4, 78, 1437, 24, 16, 182, 15651, 1468, 111, 939, 21, 19419, 667, 24, 15, 4, 200, 1437, 939, 95, 1705, 75, 146, 5, 2451, 20951, 173, 13, 162, 7, 3042, 5, 2564, 939, 770, 4, 371, 1437, 24, 21, 350, 614, 13, 162, 8, 74, 240, 10, 740, 5602, 81, 5, 9215, 4, 150, 939, 399, 75, 206, 5, 8089, 58, 25, 1844, 25, 5, 2170, 1437, 24, 21, 202, 1256, 4, 939, 115, 33, 3544, 1613, 159, 10, 1836, 7, 4190, 103, 9, 127, 1379, 1437, 53, 172, 939, 216, 24, 74, 33, 57, 350, 765, 13, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] I tried hard to make this work because it is beautiful but ended up returning it. first it is very delicate material - i was terrified trying it on. second i just couldn't make the drawstring work for me to achieve the fit i wanted. third it was too low for me and would need a cami over the slip. while i didn't think the colors were as deep as the picture it was still pretty. i could have possibly gone down a size to fix some of my concerns but then i know it would have been too short for 2023-10-22T16:21:07Z
10461 -1 0 [0, 970, 58, 117, 6173, 1437, 24, 18, 41, 22, 20412, 5451, 113, 8, 802, 24, 429, 356, 205, 19, 10, 2579, 16576, 23, 41, 2568, 3312, 4, 5, 2292, 463, 3463, 11458, 124, 1326, 101, 14711, 6399, 1468, 4, 15, 5, 1104, 1732, 9, 42, 1437, 24, 16, 21230, 27407, 19, 41, 1021, 38615, 3195, 8, 1104, 14, 95, 1326, 11522, 4, 25, 10, 11044, 219, 2491, 417, 939, 21, 12144, 7, 465, 2185, 7358, 11, 10, 4761, 4, 24, 473, 45, 356, 101, 5, 10582, 8, 5, 24150, 1087, 1722, 66, 4, 939, 619, 101, 42, 56, 7, 33, 57, 33914, 8, 21222, 11, 13, 42, 10582, 4, 939, 437, 41, 38631, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] "There were no reviews it's an ""online exclusive"" and thought it might look good with a nice skirt at an upcoming wedding. the spandex jersey back looks like sweat shirt material. on the white version of this it is mismatched with an oatmeal color and white that just looks awful. as a busty 36d i was stunned to find myself swimming in a medium. it does not look like the photograph and the sleeve billow out. i feel like this had to have been clipped and tucked in for this photograph. i'm an anth" 2023-10-22T16:21:07Z
10431 0 1 [0, 43670, 3215, 1836, 316, 1437, 24, 10698, 53, 16427, 10, 5262, 828, 11, 5, 1084, 22580, 4, 67, 169, 350, 251, 1437, 2323, 874, 127, 15145, 4, 5, 3588, 16, 2721, 35, 17766, 909, 3195, 1437, 2579, 10199, 1437, 372, 5397, 4, 24, 18, 67, 5, 761, 9, 3588, 14, 531, 2564, 157, 7, 356, 205, 4, 939, 56, 7, 671, 4318, 4, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] Ordered size 12 it fits but pulls a tiny bit in the midsection. also way too long hits below my knees. the dress is beautiful: crisp black color nice fabric great neck. it's also the kind of dress that must fit well to look good. i had to return mine. 2023-10-22T16:21:07Z
3. Query the Feature Store
In addition to transforming the data and saving in S3 bucket, the processing job populates the feature store with the transformed and balanced data. Let’s query this data using Amazon Athena.
3.1. Export training, validation, and test datasets from the Feature Store
Here you will do the export only for the training dataset, as an example.
Use athena_query() function to create an Athena query for the defined above Feature Group. Then you can pull the table name of the Amazon Glue Data Catalog table which is auto-generated by Feature Store.
feature_store_query = feature_group.athena_query()
feature_store_table = feature_store_query.table_name
query_string = """
SELECT date,
review_id,
sentiment,
label_id,
input_ids,
review_body
FROM "{}"
WHERE split_type='train'
LIMIT 5
""".format(feature_store_table)
print('Glue Catalog table name: {}'.format(feature_store_table))
print('Running query: {}'.format(query_string))
Glue Catalog table name: reviews_feature_group_1697991113_1697991636
Running query:
SELECT date,
review_id,
sentiment,
label_id,
input_ids,
review_body
FROM "reviews_feature_group_1697991113_1697991636"
WHERE split_type='train'
LIMIT 5
Configure the S3 location for the query results. This allows us to re-use the query results for future queries if the data has not changed. We can even share this S3 location between team members to improve query performance for common queries on data that does not change often.
output_s3_uri = 's3://{}/query_results/{}/'.format(bucket, feature_store_offline_prefix)
print(output_s3_uri)
s3://sagemaker-us-east-1-062287423314/query_results/reviews-feature-store-1697991113/
Exercise 4
Query the feature store.
Instructions: Use feature_store_query.run function passing the constructed above query string and the location of the output S3 bucket.
feature_store_query.run(
query_string=..., # query string
output_location=... # location of the output S3 bucket
)
feature_store_query.run(
### BEGIN SOLUTION - DO NOT delete this comment for grading purposes
query_string=query_string,
output_location=output_s3_uri
### END SOLUTION - DO NOT delete this comment for grading purposes
)
feature_store_query.wait()
import pandas as pd
pd.set_option("max_colwidth", 100)
df_feature_store = feature_store_query.as_dataframe()
df_feature_store
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| date | review_id | sentiment | label_id | input_ids | review_body | |
|---|---|---|---|---|---|---|
| 0 | 2023-10-22T16:21:07Z | 4839 | 0 | 1 | [0, 713, 16, 10, 1256, 15652, 16338, 4, 5, 1836, 290, 74, 2564, 951, 269, 157, 54, 18, 59, 10, 6... | This is a pretty adorable jumper. the size 8 would fit someone really well who's about a typical... |
| 1 | 2023-10-22T16:21:07Z | 19046 | 0 | 1 | [0, 100, 269, 6640, 5, 10199, 8, 5, 1521, 9, 42, 23204, 1437, 53, 5, 21764, 10601, 23, 41, 8372,... | I really liked the fabric and the design of this sweater but the sleeves hung at an odd length ... |
| 2 | 2023-10-22T16:21:07Z | 1709 | 1 | 2 | [0, 100, 1381, 42, 15, 23, 5, 1400, 11, 5, 1675, 1836, 24, 376, 11, 8, 802, 2085, 24, 34, 103, 8... | I tried this on at the store in the regular size it came in and thought maybe it has some potent... |
| 3 | 2023-10-22T16:21:07Z | 12905 | 1 | 2 | [0, 243, 18, 1365, 7, 2649, 5, 2051, 1254, 14, 146, 42, 299, 780, 4, 627, 10199, 7540, 594, 198,... | It's easy to miss the fine details that make this top special.the fabric inset around the collar... |
| 4 | 2023-10-22T16:21:07Z | 5850 | 1 | 2 | [0, 100, 657, 5, 3195, 1437, 5, 10199, 8, 5, 2496, 36, 20345, 11, 5, 1421, 2347, 43, 53, 11, 201... | I love the color the fabric and the style (especially in the model shots) but in reality the c... |
Review the Feature Store in SageMaker Studio

3.2. Export TSV from Feature Store
Save the output as a TSV file:
df_feature_store.to_csv('./feature_store_export.tsv',
sep='\t',
index=False,
header=True)
!head -n 5 ./feature_store_export.tsv
date review_id sentiment label_id input_ids review_body
2023-10-22T16:21:07Z 4839 0 1 [0, 713, 16, 10, 1256, 15652, 16338, 4, 5, 1836, 290, 74, 2564, 951, 269, 157, 54, 18, 59, 10, 6097, 1836, 231, 8, 2085, 195, 108, 401, 845, 939, 437, 195, 108, 466, 113, 8, 24, 21, 350, 765, 4, 24, 18, 1531, 8, 2299, 430, 4, 939, 1017, 3680, 3568, 24, 4, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] "This is a pretty adorable jumper. the size 8 would fit someone really well who's about a typical size 6 and maybe 5'6"". i'm 5'9"" and it was too short. it's fun and definitely different. i'd otherwise wear it."
2023-10-22T16:21:07Z 19046 0 1 [0, 100, 269, 6640, 5, 10199, 8, 5, 1521, 9, 42, 23204, 1437, 53, 5, 21764, 10601, 23, 41, 8372, 5933, 36, 2362, 169, 7, 1920, 106, 62, 101, 15, 5, 1421, 43, 8, 5, 23204, 21, 739, 15, 162, 4, 939, 33, 4007, 10762, 53, 524, 3680, 4716, 1459, 4, 9574, 939, 56, 7, 671, 42, 4, 7785, 643, 32, 519, 357, 6620, 4, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] I really liked the fabric and the design of this sweater but the sleeves hung at an odd length (no way to push them up like on the model) and the sweater was large on me. i have broad shoulders but am otherwise petite. unfortunately i had to return this. glad others are having better luck.
2023-10-22T16:21:07Z 1709 1 2 [0, 100, 1381, 42, 15, 23, 5, 1400, 11, 5, 1675, 1836, 24, 376, 11, 8, 802, 2085, 24, 34, 103, 801, 16, 939, 2740, 24, 13, 162, 11, 10, 4716, 1459, 187, 14, 18, 99, 939, 524, 4, 939, 8266, 5, 3737, 77, 939, 78, 300, 24, 2053, 24, 1979, 75, 269, 356, 235, 53, 1021, 22984, 1437, 24, 18, 727, 207, 2770, 8, 34203, 4, 3568, 24, 19, 22877, 10844, 1437, 2084, 6149, 1033, 1437, 4112, 6149, 1033, 1437, 3046, 8, 24, 18, 95, 2422, 6344, 15, 7001, 62, 50, 159, 4, 939, 1017, 907, 42, 81, 8, 81, 456, 396, 10, 2980, 4, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] I tried this on at the store in the regular size it came in and thought maybe it has some potential is i ordered it for me in a petite since that's what i am. i ignored the package when i first got it thinking it wouldn't really look right but omg it's 100% amazing and flattering. wear it with skinny jeans leggings jeggings whatever and it's just super awesome on dressed up or down. i'd buy this over and over again without a doubt.
2023-10-22T16:21:07Z 12905 1 2 [0, 243, 18, 1365, 7, 2649, 5, 2051, 1254, 14, 146, 42, 299, 780, 4, 627, 10199, 7540, 594, 198, 5, 19008, 359, 760, 2968, 32561, 16, 41, 20372, 25734, 9410, 2428, 6084, 5780, 31669, 5526, 19, 155, 417, 29815, 26370, 5326, 219, 8, 699, 16721, 1344, 359, 16, 20856, 19, 10, 15651, 22990, 4, 5, 16721, 1344, 32, 2295, 12, 24882, 11, 10, 182, 12405, 1437, 31910, 219, 169, 4, 1437, 1437, 1437, 2721, 223, 10, 23204, 1437, 657, 5, 299, 18, 1457, 10490, 356, 1437, 10698, 326, 1872, 1437, 45, 350, 11708, 4, 1437, 1437, 1437, 1437, 47, 429, 33, 7, 3568, 10, 18052, 16979, 11689, 50, 109, 396, 65, 11807, 142, 9, 5, 5397, 1902, 8, 2, 1, 1, 1, 1, 1, 1, 1, 1] It's easy to miss the fine details that make this top special.the fabric inset around the collar & front placket is an abstract blossoming spring branch print overlaid with 3d decorative embroidery and clear sequins & is trimmed with a delicate lace. the sequins are eye-catching in a very subtle shimmery way. beautiful under a sweater love the top's double layer look fits tts not too sheer. you might have to wear a strapless bra or do without one altogether because of the neckline and
Upload TSV to the S3 bucket:
!aws s3 cp ./feature_store_export.tsv s3://$bucket/feature_store/feature_store_export.tsv
upload: ./feature_store_export.tsv to s3://sagemaker-us-east-1-062287423314/feature_store/feature_store_export.tsv
Check the file in the S3 bucket:
!aws s3 ls --recursive s3://$bucket/feature_store/feature_store_export.tsv
2023-10-22 16:29:47 4954 feature_store/feature_store_export.tsv
3.3. Check that the dataset in the Feature Store is balanced by sentiment
Now you can setup an Athena query to check that the stored dataset is balanced by the target class sentiment.
Exercise 5
Write an SQL query to count the total number of the reviews per sentiment stored in the Feature Group.
Instructions: Pass the SQL statement of the form
SELECT category_column, COUNT(*) AS new_column_name
FROM table_name
GROUP BY category_column
into the variable query_string_count_by_sentiment. Here you would need to use the column sentiment and give a name count_reviews to the new column with the counts.
feature_store_query_2 = feature_group.athena_query()
# Replace all None
### BEGIN SOLUTION - DO NOT delete this comment for grading purposes
query_string_count_by_sentiment = """
SELECT sentiment, COUNT(*) AS count_reviews
FROM "{}"
GROUP BY sentiment
""".format(feature_store_table)
### END SOLUTION - DO NOT delete this comment for grading purposes
Exercise 6
Query the feature store.
Instructions: Use run function of the Feature Store query, passing the new query string query_string_count_by_sentiment. The output S3 bucket will remain unchanged. You can follow the example above.
feature_store_query_2.run(
### BEGIN SOLUTION - DO NOT delete this comment for grading purposes
query_string=query_string_count_by_sentiment,
output_location=output_s3_uri
### END SOLUTION - DO NOT delete this comment for grading purposes
)
feature_store_query_2.wait()
df_count_by_sentiment = feature_store_query_2.as_dataframe()
df_count_by_sentiment
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| sentiment | count_reviews | |
|---|---|---|
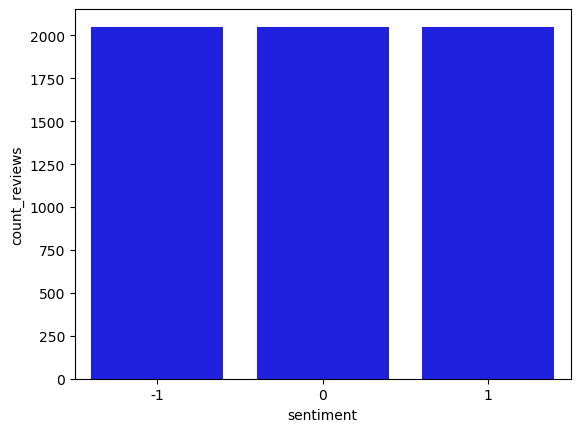
| 0 | 1 | 2051 |
| 1 | 0 | 2051 |
| 2 | -1 | 2051 |
Exercise 7
Visualize the result of the query in the bar plot, showing the count of the reviews by sentiment value.
Instructions: Pass the resulting data frame df_count_by_sentiment into the barplot function of the seaborn library.
sns.barplot(
data=...,
x='...',
y='...',
color="blue"
)
# %matplotlib inline
import seaborn as sns
sns.barplot(
### BEGIN SOLUTION - DO NOT delete this comment for grading purposes
data=df_count_by_sentiment,
x="sentiment",
y="count_reviews",
### END SOLUTION - DO NOT delete this comment for grading purposes
color="blue"
)
<matplotlib.axes._subplots.AxesSubplot at 0x7fb05fb32150>
Upload the notebook and prepare_data.py file into S3 bucket for grading purposes.
Note: you may need to save the file before the upload.
!aws s3 cp ./C2_W1_Assignment.ipynb s3://$bucket/C2_W1_Assignment_Learner.ipynb
!aws s3 cp ./src/prepare_data.py s3://$bucket/src/C2_W1_prepare_data_Learner.py
upload: ./C2_W1_Assignment.ipynb to s3://sagemaker-us-east-1-062287423314/C2_W1_Assignment_Learner.ipynb
upload: src/prepare_data.py to s3://sagemaker-us-east-1-062287423314/src/C2_W1_prepare_data_Learner.py
Please go to the main lab window and click on Submit button (see the Finish the lab section of the instructions).