Coursera
Detect data bias with Amazon SageMaker Clarify
Introduction
Bias can be present in your data before any model training occurs. Inspecting the dataset for bias can help detect collection gaps, inform your feature engineering, and understand societal biases the dataset may reflect. In this lab you will analyze bias on the dataset, generate and analyze bias report, and prepare the dataset for the model training.
Table of Contents
- 1. Analyze the dataset
- 2. Analyze class imbalance on the dataset with Amazon SageMaker Clarify
- 3. Balance the dataset by
product_categoryandsentiment - 4. Analyze bias on balanced dataset with Amazon SageMaker Clarify
First, let’s install and import required modules.
# please ignore warning messages during the installation
!pip install --disable-pip-version-check -q sagemaker==2.35.0
!pip install -q protobuf==3.20.*
[33mDEPRECATION: pyodbc 4.0.0-unsupported has a non-standard version number. pip 23.3 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pyodbc or contact the author to suggest that they release a version with a conforming version number. Discussion can be found at https://github.com/pypa/pip/issues/12063[0m[33m
[0m[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
sparkmagic 0.20.4 requires nest-asyncio==1.5.5, but you have nest-asyncio 1.5.7 which is incompatible.[0m[31m
[0m[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0m[33mDEPRECATION: pyodbc 4.0.0-unsupported has a non-standard version number. pip 23.3 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pyodbc or contact the author to suggest that they release a version with a conforming version number. Discussion can be found at https://github.com/pypa/pip/issues/12063[0m[33m
[0m[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0m
import boto3
import sagemaker
import pandas as pd
import numpy as np
import botocore
config = botocore.config.Config(user_agent_extra='dlai-pds/c1/w2')
# low-level service client of the boto3 session
sm = boto3.client(service_name='sagemaker',
config=config)
sess = sagemaker.Session(sagemaker_client=sm)
bucket = sess.default_bucket()
role = sagemaker.get_execution_role()
region = sess.boto_region_name
/opt/conda/lib/python3.7/site-packages/boto3/compat.py:82: PythonDeprecationWarning: Boto3 will no longer support Python 3.7 starting December 13, 2023. To continue receiving service updates, bug fixes, and security updates please upgrade to Python 3.8 or later. More information can be found here: https://aws.amazon.com/blogs/developer/python-support-policy-updates-for-aws-sdks-and-tools/
warnings.warn(warning, PythonDeprecationWarning)
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format='retina'
1. Analyze the dataset
1.1. Create a pandas data frame from the CSV file
Create a pandas dataframe from each of the product categories and concatenate them into one.
!aws s3 cp 's3://dlai-practical-data-science/data/transformed/womens_clothing_ecommerce_reviews_transformed.csv' ./
download: s3://dlai-practical-data-science/data/transformed/womens_clothing_ecommerce_reviews_transformed.csv to ./womens_clothing_ecommerce_reviews_transformed.csv
path = './womens_clothing_ecommerce_reviews_transformed.csv'
df = pd.read_csv(path)
df.head()
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| sentiment | review_body | product_category | |
|---|---|---|---|
| 0 | 1 | If this product was in petite i would get the... | Blouses |
| 1 | 1 | Love this dress! it's sooo pretty. i happene... | Dresses |
| 2 | 0 | I had such high hopes for this dress and reall... | Dresses |
| 3 | 1 | I love love love this jumpsuit. it's fun fl... | Pants |
| 4 | 1 | This shirt is very flattering to all due to th... | Blouses |
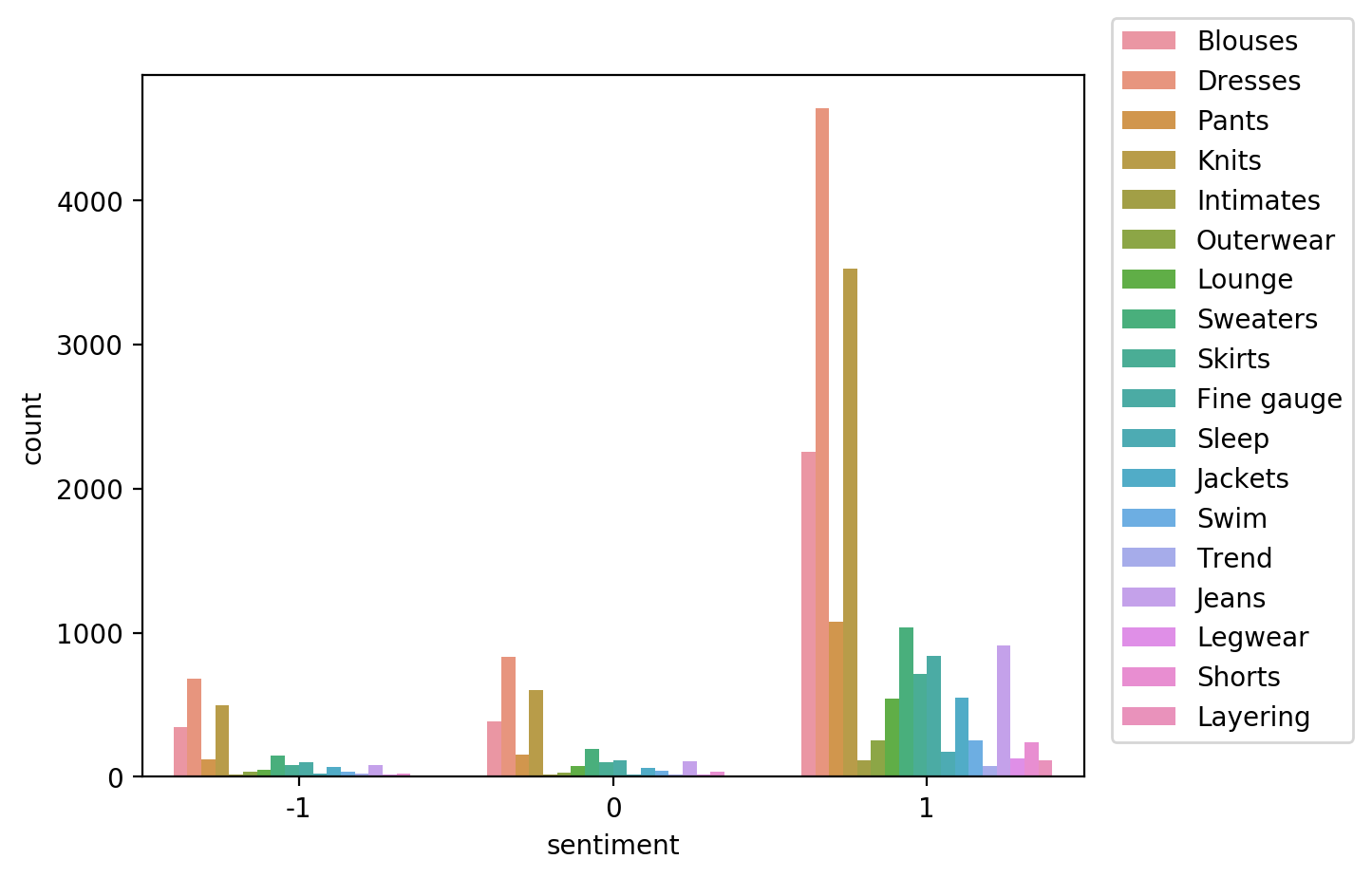
As you saw in the previous lab, there are way more positive reviews than negative or neutral. Such a dataset is called unbalanced.
In this case, using a relatively small data subset you could visualize the occurring unbalances. At scale, you would need to perform bias analysis. Let’s use this dataset as an example.
import seaborn as sns
sns.countplot(data=df, x='sentiment', hue='product_category')
plt.legend(loc='upper right',bbox_to_anchor=(1.3, 1.1))
<matplotlib.legend.Legend at 0x7fbc34978b50>
1.2. Upload the dataset to S3 bucket
Upload the dataset to a private S3 bucket in a folder called bias/unbalanced.
data_s3_uri_unbalanced = sess.upload_data(bucket=bucket,
key_prefix='bias/unbalanced',
path='./womens_clothing_ecommerce_reviews_transformed.csv')
data_s3_uri_unbalanced
's3://sagemaker-us-east-1-109150271829/bias/unbalanced/womens_clothing_ecommerce_reviews_transformed.csv'
You can review the uploaded CSV file in the S3 bucket.
Instructions:
- open the link
- click on the S3 bucket name
sagemaker-us-east-1-ACCOUNT - go to the folder
bias/unbalanced - check the existence of the file
womens_clothing_ecommerce_reviews_transformed.csv
from IPython.core.display import display, HTML
display(HTML('<b>Review <a target="top" href="https://s3.console.aws.amazon.com/s3/home?region={}#">Amazon S3 bucket</a></b>'.format(region)))
Review Amazon S3 bucket
2. Analyze class imbalance on the dataset with Amazon SageMaker Clarify
Let’s analyze bias in sentiment with respect to the product_category facet on the dataset.
2.1. Configure a DataConfig
Information about the input data needs to be provided to the processor. This can be done with the DataConfig of the Clarify container. It stores information about the dataset to be analyzed, for example the dataset file, its format, headers and labels.
Exercise 1
Configure a DataConfig for Clarify.
Instructions: Use DataConfig to configure the target column ('sentiment' label), data input (data_s3_uri_unbalanced) and output paths (bias_report_unbalanced_output_path) with their formats (header names and the dataset type):
data_config_unbalanced = clarify.DataConfig(
s3_data_input_path=..., # S3 object path containing the unbalanced dataset
s3_output_path=..., # path to store the output
label='...', # target column
headers=df_unbalanced.columns.to_list(),
dataset_type='text/csv'
)
from sagemaker import clarify
bias_report_unbalanced_output_path = 's3://{}/bias/generated_bias_report/unbalanced'.format(bucket)
data_config_unbalanced = clarify.DataConfig(
### BEGIN SOLUTION - DO NOT delete this comment for grading purposes
s3_data_input_path=data_s3_uri_unbalanced,
s3_output_path=bias_report_unbalanced_output_path,
label="sentiment",
### END SOLUTION - DO NOT delete this comment for grading purposes
headers=df.columns.to_list(),
dataset_type='text/csv'
)
2.2. Configure BiasConfig
Bias is measured by calculating a metric and comparing it across groups. To compute it, you will specify the required information in the BiasConfig API. SageMaker Clarify needs the sensitive columns (facet_name) and the desirable outcomes (label_values_or_threshold). Here product_category is the sensitive facet and the desired outcome is with the sentiment==1.
SageMaker Clarify can handle both categorical and continuous data for label_values_or_threshold. In this case you are using categorical data.
bias_config_unbalanced = clarify.BiasConfig(
label_values_or_threshold=[1], # desired sentiment
facet_name='product_category' # sensitive column (facet)
)
2.3. Configure Amazon SageMaker Clarify as a processing job
Now you need to construct an object called SageMakerClarifyProcessor. This allows you to scale the process of data bias detection using two parameters, instance_count and instance_type. Instance_count represents how many nodes you want in the distributor cluster during the data detection. Instance_type specifies the processing capability (compute capacity, memory capacity) available for each one of those nodes. For the purposes of this lab, you will use a relatively small instance type. Please refer to this link for additional instance types that may work for your use case outside of this lab.
clarify_processor_unbalanced = clarify.SageMakerClarifyProcessor(role=role,
instance_count=1,
instance_type='ml.m5.large',
sagemaker_session=sess)
2.4. Run the Amazon SageMaker Clarify processing job
Exercise 2
Run the configured processing job to compute the requested bias methods of the input data
Instructions: Apply the run_pre_training_bias method to the configured Clarify processor, passing the configured input/output data (data_config_unbalanced), configuration of sensitive groups (bias_config_unbalanced) with the other job setup parameters:
clarify_processor_unbalanced.run_pre_training_bias(
data_config=..., # configured input/output data
data_bias_config=..., # configured sensitive groups
methods=["CI", "DPL", "KL", "JS", "LP", "TVD", "KS"], # selector of a subset of potential metrics
wait=False, # whether the call should wait until the job completes (default: True)
logs=False # whether to show the logs produced by the job. Only meaningful when wait is True (default: True)
)
clarify_processor_unbalanced.run_pre_training_bias(
### BEGIN SOLUTION - DO NOT delete this comment for grading purposes
data_config=data_config_unbalanced,
data_bias_config=bias_config_unbalanced,
### END SOLUTION - DO NOT delete this comment for grading purposes
methods=["CI", "DPL", "KL", "JS", "LP", "TVD", "KS"],
wait=False,
logs=False
)
Job Name: Clarify-Pretraining-Bias-2023-09-19-06-11-10-497
Inputs: [{'InputName': 'dataset', 'AppManaged': False, 'S3Input': {'S3Uri': 's3://sagemaker-us-east-1-109150271829/bias/unbalanced/womens_clothing_ecommerce_reviews_transformed.csv', 'LocalPath': '/opt/ml/processing/input/data', 'S3DataType': 'S3Prefix', 'S3InputMode': 'File', 'S3DataDistributionType': 'FullyReplicated', 'S3CompressionType': 'None'}}, {'InputName': 'analysis_config', 'AppManaged': False, 'S3Input': {'S3Uri': 's3://sagemaker-us-east-1-109150271829/bias/generated_bias_report/unbalanced/analysis_config.json', 'LocalPath': '/opt/ml/processing/input/config', 'S3DataType': 'S3Prefix', 'S3InputMode': 'File', 'S3DataDistributionType': 'FullyReplicated', 'S3CompressionType': 'None'}}]
Outputs: [{'OutputName': 'analysis_result', 'AppManaged': False, 'S3Output': {'S3Uri': 's3://sagemaker-us-east-1-109150271829/bias/generated_bias_report/unbalanced', 'LocalPath': '/opt/ml/processing/output', 'S3UploadMode': 'EndOfJob'}}]
run_unbalanced_bias_processing_job_name = clarify_processor_unbalanced.latest_job.job_name
print(run_unbalanced_bias_processing_job_name)
Clarify-Pretraining-Bias-2023-09-19-06-11-10-497
2.5. Run and review the Amazon SageMaker Clarify processing job on the unbalanced dataset
Review the created Amazon SageMaker Clarify processing job and the Cloud Watch logs.
Instructions:
- open the link
- note that you are in the section Amazon SageMaker -> Processing jobs
- check the processing job name
- note which other properties of the processing job you can see in the console
from IPython.core.display import display, HTML
display(HTML('<b>Review <a target="blank" href="https://console.aws.amazon.com/sagemaker/home?region={}#/processing-jobs/{}">processing job</a></b>'.format(region, run_unbalanced_bias_processing_job_name)))
Review processing job
Instructions:
- open the link
- open the log stream with the name, which starts from the processing job name
- have a quick look at the log messages
from IPython.core.display import display, HTML
display(HTML('<b>Review <a target="blank" href="https://console.aws.amazon.com/cloudwatch/home?region={}#logStream:group=/aws/sagemaker/ProcessingJobs;prefix={};streamFilter=typeLogStreamPrefix">CloudWatch logs</a> after about 5 minutes</b>'.format(region, run_unbalanced_bias_processing_job_name)))
Review CloudWatch logs after about 5 minutes
running_processor = sagemaker.processing.ProcessingJob.from_processing_name(processing_job_name=run_unbalanced_bias_processing_job_name,
sagemaker_session=sess)
This cell will take approximately 5-10 minutes to run.
%%time
running_processor.wait(logs=False)
.........................................................!CPU times: user 254 ms, sys: 45.4 ms, total: 300 ms
Wall time: 4min 49s
2.6. Analyze unbalanced bias report
In this run, you analyzed bias for sentiment relative to the product_category for the unbalanced data. Let’s have a look at the bias report.
List the files in the output path bias_report_unbalanced_output_path:
!aws s3 ls $bias_report_unbalanced_output_path/
2023-09-19 06:17:23 31732 analysis.json
2023-09-19 06:11:11 346 analysis_config.json
2023-09-19 06:17:23 1255560 report.html
2023-09-19 06:17:23 995353 report.ipynb
2023-09-19 06:17:23 871302 report.pdf
Download generated bias report from S3 bucket:
!aws s3 cp --recursive $bias_report_unbalanced_output_path ./generated_bias_report/unbalanced/
download: s3://sagemaker-us-east-1-109150271829/bias/generated_bias_report/unbalanced/analysis_config.json to generated_bias_report/unbalanced/analysis_config.json
download: s3://sagemaker-us-east-1-109150271829/bias/generated_bias_report/unbalanced/analysis.json to generated_bias_report/unbalanced/analysis.json
download: s3://sagemaker-us-east-1-109150271829/bias/generated_bias_report/unbalanced/report.pdf to generated_bias_report/unbalanced/report.pdf
download: s3://sagemaker-us-east-1-109150271829/bias/generated_bias_report/unbalanced/report.html to generated_bias_report/unbalanced/report.html
download: s3://sagemaker-us-east-1-109150271829/bias/generated_bias_report/unbalanced/report.ipynb to generated_bias_report/unbalanced/report.ipynb
Review the downloaded bias report (in HTML format):
from IPython.core.display import display, HTML
display(HTML('<b>Review <a target="blank" href="./generated_bias_report/unbalanced/report.html">unbalanced bias report</a></b>'))
Review unbalanced bias report
The bias report shows a number of metrics, but here you can focus on just two of them:
- Class Imbalance (CI). Measures the imbalance in the number of members between different facet values. Answers the question, does a
product_categoryhave disproportionately more reviews than others? Values of CI will become equal for even distribution between facets. Here, different CI values show the existence of imbalance. - Difference in Positive Proportions in Labels (DPL). Measures the imbalance of positive outcomes between different facet values. Answers the question, does a
product_categoryhave disproportionately higher ratings than others? With the range over the interval from -1 to 1, if there is no bias, you want to see this value as close as possible to zero. Here, non-zero values indicate the imbalances.
3. Balance the dataset by product_category and sentiment
Let’s balance the dataset by product_category and sentiment. Then you can configure and run SageMaker Clarify processing job to analyze the bias of it. Which metrics values do you expect to see in the bias report?
df_grouped_by = df.groupby(['product_category', 'sentiment'])
df_balanced = df_grouped_by.apply(lambda x: x.sample(df_grouped_by.size().min()).reset_index(drop=True))
df_balanced
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| sentiment | review_body | product_category | |||
|---|---|---|---|---|---|
| product_category | sentiment | ||||
| Blouses | -1 | 0 | -1 | I ordered a small which is my usual retailer ... | Blouses |
| 1 | -1 | I agree with the other review. the fabric and ... | Blouses | ||
| 2 | -1 | I was drawn to this top because of the interes... | Blouses | ||
| 3 | -1 | I love this shirt love love love it. i am a c... | Blouses | ||
| 4 | -1 | If you have anything larger than an a cup thi... | Blouses | ||
| ... | ... | ... | ... | ... | ... |
| Trend | 1 | 4 | 1 | So different than anything in my closet. it's ... | Trend |
| 5 | 1 | I found this at my local store and ended up bu... | Trend | ||
| 6 | 1 | I just received these sweaters............coul... | Trend | ||
| 7 | 1 | Beautiful dress. when you look at it on the ha... | Trend | ||
| 8 | 1 | This sweater tee is made from a fine but subst... | Trend |
486 rows × 3 columns
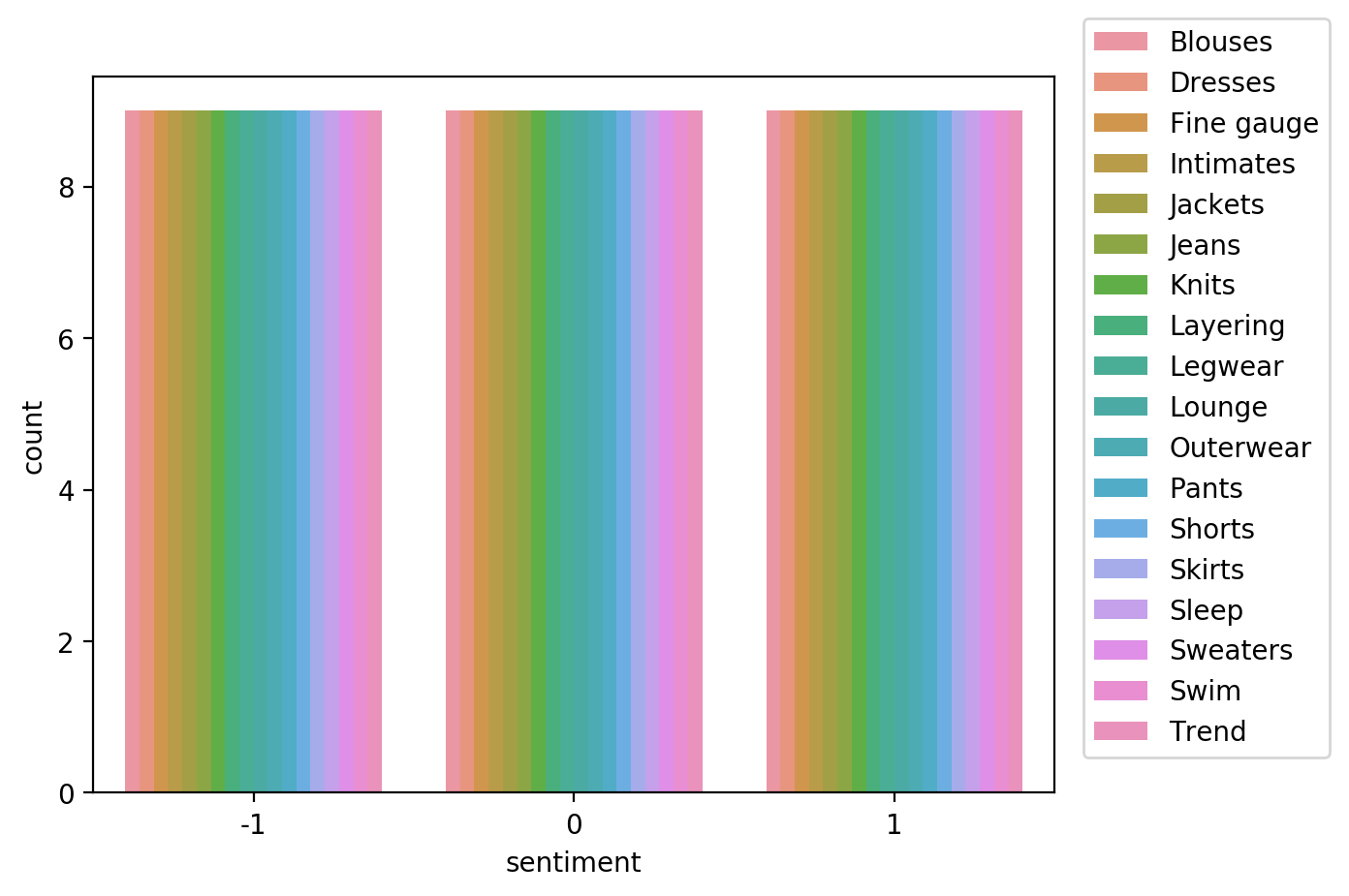
Visualize the distribution of review sentiment in the balanced dataset.
import seaborn as sns
sns.countplot(data=df_balanced, x='sentiment', hue='product_category')
plt.legend(loc='upper right',bbox_to_anchor=(1.3, 1.1))
<matplotlib.legend.Legend at 0x7fbc2dca7650>
4. Analyze bias on balanced dataset with Amazon SageMaker Clarify
Let’s analyze bias in sentiment with respect to the product_category facet on your balanced dataset.
Save and upload balanced data to S3 bucket.
path_balanced = './womens_clothing_ecommerce_reviews_balanced.csv'
df_balanced.to_csv(path_balanced, index=False, header=True)
data_s3_uri_balanced = sess.upload_data(bucket=bucket, key_prefix='bias/balanced', path=path_balanced)
data_s3_uri_balanced
's3://sagemaker-us-east-1-109150271829/bias/balanced/womens_clothing_ecommerce_reviews_balanced.csv'
You can review the uploaded CSV file in the S3 bucket and prefix bias/balanced.
from IPython.core.display import display, HTML
display(HTML('<b>Review <a target="top" href="https://s3.console.aws.amazon.com/s3/home?region={}#">Amazon S3 bucket</a></b>'.format(region)))
Review Amazon S3 bucket
4.1. Configure a DataConfig
Exercise 3
Configure a DataConfig for Clarify to analyze bias on the balanced dataset.
Instructions: Pass the S3 object path containing the balanced dataset, the path to store the output (bias_report_balanced_output_path) and the target column. You can use exercise 1 as an example.
from sagemaker import clarify
bias_report_balanced_output_path = 's3://{}/bias/generated_bias_report/balanced'.format(bucket)
data_config_balanced = clarify.DataConfig(
### BEGIN SOLUTION - DO NOT delete this comment for grading purposes
s3_data_input_path=data_s3_uri_balanced,
s3_output_path=bias_report_balanced_output_path,
label="sentiment",
### END SOLUTION - DO NOT delete this comment for grading purposes
headers=df_balanced.columns.to_list(),
dataset_type='text/csv'
)
4.2. Configure BiasConfig
BiasConfig for the balanced dataset will have the same settings as before.
bias_config_balanced = clarify.BiasConfig(
label_values_or_threshold=[1], # desired sentiment
facet_name='product_category' # sensitive column (facet)
)
4.3. Configure SageMaker Clarify as a processing job
SageMakerClarifyProcessor object will also have the same parameters.
clarify_processor_balanced = clarify.SageMakerClarifyProcessor(role=role,
instance_count=1,
instance_type='ml.m5.large',
sagemaker_session=sess)
4.4. Run the Amazon SageMaker Clarify processing job
Exercise 4
Run the configured processing job for the balanced dataset.
Instructions: Apply the run_pre_training_bias method to the configured Clarify processor, passing the input/output data, configuration of sensitive groups with the other job setup parameters. You can use exercise 2 as an example.
clarify_processor_balanced.run_pre_training_bias(
### BEGIN SOLUTION - DO NOT delete this comment for grading purposes
data_config=data_config_balanced,
data_bias_config=bias_config_balanced,
### END SOLUTION - DO NOT delete this comment for grading purposes
methods=["CI", "DPL", "KL", "JS", "LP", "TVD", "KS"],
wait=False,
logs=False
)
Job Name: Clarify-Pretraining-Bias-2023-09-19-06-20-18-593
Inputs: [{'InputName': 'dataset', 'AppManaged': False, 'S3Input': {'S3Uri': 's3://sagemaker-us-east-1-109150271829/bias/balanced/womens_clothing_ecommerce_reviews_balanced.csv', 'LocalPath': '/opt/ml/processing/input/data', 'S3DataType': 'S3Prefix', 'S3InputMode': 'File', 'S3DataDistributionType': 'FullyReplicated', 'S3CompressionType': 'None'}}, {'InputName': 'analysis_config', 'AppManaged': False, 'S3Input': {'S3Uri': 's3://sagemaker-us-east-1-109150271829/bias/generated_bias_report/balanced/analysis_config.json', 'LocalPath': '/opt/ml/processing/input/config', 'S3DataType': 'S3Prefix', 'S3InputMode': 'File', 'S3DataDistributionType': 'FullyReplicated', 'S3CompressionType': 'None'}}]
Outputs: [{'OutputName': 'analysis_result', 'AppManaged': False, 'S3Output': {'S3Uri': 's3://sagemaker-us-east-1-109150271829/bias/generated_bias_report/balanced', 'LocalPath': '/opt/ml/processing/output', 'S3UploadMode': 'EndOfJob'}}]
run_balanced_bias_processing_job_name = clarify_processor_balanced.latest_job.job_name
print(run_balanced_bias_processing_job_name)
Clarify-Pretraining-Bias-2023-09-19-06-20-18-593
4.5. Run and review the Clarify processing job on the balanced dataset
Review the results of the run following the links:
from IPython.core.display import display, HTML
display(HTML('<b>Review <a target="blank" href="https://console.aws.amazon.com/sagemaker/home?region={}#/processing-jobs/{}">processing job</a></b>'.format(region, run_balanced_bias_processing_job_name)))
Review processing job
from IPython.core.display import display, HTML
display(HTML('<b>Review <a target="blank" href="https://console.aws.amazon.com/cloudwatch/home?region={}#logStream:group=/aws/sagemaker/ProcessingJobs;prefix={};streamFilter=typeLogStreamPrefix">CloudWatch logs</a> after about 5 minutes</b>'.format(region, run_balanced_bias_processing_job_name)))
Review CloudWatch logs after about 5 minutes
running_processor = sagemaker.processing.ProcessingJob.from_processing_name(processing_job_name=run_balanced_bias_processing_job_name,
sagemaker_session=sess)
This cell will take approximately 5-10 minutes to run.
%%time
running_processor.wait(logs=False)
............................................................................!CPU times: user 357 ms, sys: 21.7 ms, total: 379 ms
Wall time: 6min 25s
4.6. Analyze balanced bias report
List the files in the output path bias_report_balanced_output_path:
!aws s3 ls $bias_report_balanced_output_path/
2023-09-19 06:26:44 29889 analysis.json
2023-09-19 06:20:19 346 analysis_config.json
2023-09-19 06:26:44 1231056 report.html
2023-09-19 06:26:44 970849 report.ipynb
2023-09-19 06:26:44 858966 report.pdf
Download generated bias report from S3 bucket:
!aws s3 cp --recursive $bias_report_balanced_output_path ./generated_bias_report/balanced/
download: s3://sagemaker-us-east-1-109150271829/bias/generated_bias_report/balanced/analysis_config.json to generated_bias_report/balanced/analysis_config.json
download: s3://sagemaker-us-east-1-109150271829/bias/generated_bias_report/balanced/analysis.json to generated_bias_report/balanced/analysis.json
download: s3://sagemaker-us-east-1-109150271829/bias/generated_bias_report/balanced/report.pdf to generated_bias_report/balanced/report.pdf
download: s3://sagemaker-us-east-1-109150271829/bias/generated_bias_report/balanced/report.ipynb to generated_bias_report/balanced/report.ipynb
download: s3://sagemaker-us-east-1-109150271829/bias/generated_bias_report/balanced/report.html to generated_bias_report/balanced/report.html
Review the downloaded bias report (in HTML format):
from IPython.core.display import display, HTML
display(HTML('<b>Review <a target="blank" href="./generated_bias_report/balanced/report.html">balanced bias report</a></b>'))
Review balanced bias report
In this run, you analyzed bias for sentiment relative to the product_category for the balanced data. Note that the Class Imbalance (CI) metric is equal across all product categories for the target label, sentiment. And Difference in Positive Proportions in Labels (DPL) metric values are zero.
Upload the notebook into S3 bucket for grading purposes.
Note: you may need to click on “Save” button before the upload.
!aws s3 cp ./C1_W2_Assignment.ipynb s3://$bucket/C1_W2_Assignment_Learner.ipynb
upload: ./C1_W2_Assignment.ipynb to s3://sagemaker-us-east-1-109150271829/C1_W2_Assignment_Learner.ipynb
Please go to the main lab window and click on Submit button (see the Finish the lab section of the instructions).