Coursera
Ungraded lab: Manual Feature Engineering
Welcome, during this ungraded lab you are going to perform feature engineering using TensorFlow and Keras. By having a deeper understanding of the problem you are dealing with and proposing transformations to the raw features you will see how the predictive power of your model increases. In particular you will:
- Define the model using feature columns.
- Use Lambda layers to perform feature engineering on some of these features.
- Compare the training history and predictions of the model before and after feature engineering.
Note: This lab has some tweaks compared to the code you just saw on the lectures. The major one being that time-related variables are not used in the feature engineered model.
Let’s get started!
First, install and import the necessary packages, set up paths to work on and download the dataset.
Imports
# Import the packages
# Utilities
import os
import logging
# For visualization
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
# For modelling
import tensorflow as tf
from tensorflow import feature_column as fc
from tensorflow.keras import layers, models
# Set TF logger to only print errors (dismiss warnings)
logging.getLogger("tensorflow").setLevel(logging.ERROR)
Load taxifare dataset
For this lab you are going to use a tweaked version of the Taxi Fare dataset, which has been pre-processed and split beforehand.
First, create the directory where the data is going to be saved.
if not os.path.isdir("/tmp/data"):
os.makedirs("/tmp/data")
Now download the data in csv format from a cloud storage bucket.
!gsutil cp gs://cloud-training-demos/feat_eng/data/taxi*.csv /tmp/data
Copying gs://cloud-training-demos/feat_eng/data/taxi-test.csv...
Copying gs://cloud-training-demos/feat_eng/data/taxi-train.csv...
Copying gs://cloud-training-demos/feat_eng/data/taxi-valid.csv...
- [3 files][ 5.3 MiB/ 5.3 MiB]
Operation completed over 3 objects/5.3 MiB.
Let’s check that the files were copied correctly and look like we expect them to.
!ls -l /tmp/data/*.csv
-rw-r--r-- 1 root root 1113292 Aug 20 10:49 /tmp/data/taxi-test.csv
-rw-r--r-- 1 root root 3551735 Aug 20 10:49 /tmp/data/taxi-train.csv
-rw-r--r-- 1 root root 888648 Aug 20 10:49 /tmp/data/taxi-valid.csv
Everything looks fine. Notice that there are three files, one for each split of training, testing and validation.
Inspect tha data
Now take a look at the training data.
pd.read_csv('/tmp/data/taxi-train.csv').head()
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| fare_amount | passenger_count | pickup_longitude | pickup_latitude | dropoff_longitude | dropoff_latitude | hourofday | dayofweek | |
|---|---|---|---|---|---|---|---|---|
| 0 | 8.1 | 1 | -73.973731 | 40.791910 | -73.962737 | 40.767318 | 14 | 4 |
| 1 | 4.5 | 2 | -73.986495 | 40.739278 | -73.986083 | 40.730933 | 10 | 6 |
| 2 | 2.9 | 1 | -73.956043 | 40.772026 | -73.956245 | 40.773934 | 22 | 3 |
| 3 | 7.0 | 1 | -74.006557 | 40.705797 | -73.980017 | 40.713617 | 6 | 3 |
| 4 | 6.5 | 1 | -73.986443 | 40.741612 | -73.990215 | 40.746467 | 10 | 2 |
The data contains a total of 8 variables.
The fare_amount is the target, the continuous value we’ll train a model to predict. This leaves you with 7 features.
However this lab is going to focus on transforming the geospatial ones so the time features hourofday and dayofweek will be ignored.
Create an input pipeline
To load the data for the model you are going to use an experimental feature of Tensorflow that lets loading directly from a csv file.
For this you need to define some lists containing relevant information of the dataset such as the type of the columns.
# Specify which column is the target
LABEL_COLUMN = 'fare_amount'
# Specify numerical columns
# Note you should create another list with STRING_COLS if you
# had text data but in this case all features are numerical
NUMERIC_COLS = ['pickup_longitude', 'pickup_latitude',
'dropoff_longitude', 'dropoff_latitude',
'passenger_count', 'hourofday', 'dayofweek']
# A function to separate features and labels
def features_and_labels(row_data):
label = row_data.pop(LABEL_COLUMN)
return row_data, label
# A utility method to create a tf.data dataset from a CSV file
def load_dataset(pattern, batch_size=1, mode='eval'):
dataset = tf.data.experimental.make_csv_dataset(pattern, batch_size)
dataset = dataset.map(features_and_labels) # features, label
if mode == 'train':
# Notice the repeat method is used so this dataset will loop infinitely
dataset = dataset.shuffle(1000).repeat()
# take advantage of multi-threading; 1=AUTOTUNE
dataset = dataset.prefetch(1)
return dataset
Create a DNN Model in Keras
Now you will build a simple Neural Network with the numerical features as input represented by a DenseFeatures layer (which produces a dense Tensor based on the given features), two dense layers with ReLU activation functions and an output layer with a linear activation function (since this is a regression problem).
Since the model is defined using feature columns the first layer might look different to what you are used to. This is done by declaring two dictionaries, one for the inputs (defined as Input layers) and one for the features (defined as feature columns).
Then computing the DenseFeatures tensor by passing in the feature columns to the constructor of the DenseFeatures layer and passing in the inputs to the resulting tensor (this is easier to understand with code):
def build_dnn_model():
# input layer
inputs = {
colname: layers.Input(name=colname, shape=(), dtype='float32')
for colname in NUMERIC_COLS
}
# feature_columns
feature_columns = {
colname: fc.numeric_column(colname)
for colname in NUMERIC_COLS
}
# Constructor for DenseFeatures takes a list of numeric columns
# and the resulting tensor takes a dictionary of Input layers
dnn_inputs = layers.DenseFeatures(feature_columns.values())(inputs)
# two hidden layers of 32 and 8 units, respectively
h1 = layers.Dense(32, activation='relu', name='h1')(dnn_inputs)
h2 = layers.Dense(8, activation='relu', name='h2')(h1)
# final output is a linear activation because this is a regression problem
output = layers.Dense(1, activation='linear', name='fare')(h2)
# Create model with inputs and output
model = models.Model(inputs, output)
# compile model (Mean Squared Error is suitable for regression)
model.compile(optimizer='adam',
loss='mse',
metrics=[
tf.keras.metrics.RootMeanSquaredError(name='rmse'),
'mse'
])
return model
We’ll build our DNN model and inspect the model architecture.
# Save compiled model into a variable
model = build_dnn_model()
# Plot the layer architecture and relationship between input features
tf.keras.utils.plot_model(model, 'dnn_model.png', show_shapes=False, rankdir='LR')
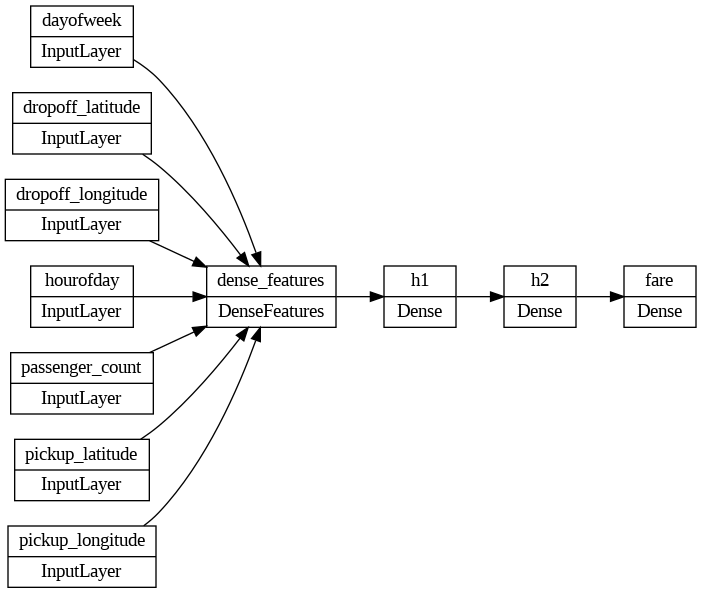
With the model architecture defined it is time to train it!
Train the model
You are going to train the model for 20 epochs using a batch size of 32.
NUM_EPOCHS = 20
TRAIN_BATCH_SIZE = 32
NUM_TRAIN_EXAMPLES = len(pd.read_csv('/tmp/data/taxi-train.csv'))
NUM_EVAL_EXAMPLES = len(pd.read_csv('/tmp/data/taxi-valid.csv'))
print(f"training split has {NUM_TRAIN_EXAMPLES} examples\n")
print(f"evaluation split has {NUM_EVAL_EXAMPLES} examples\n")
training split has 59620 examples
evaluation split has 14905 examples
Use the previously defined function to load the datasets from the original csv files.
# Training dataset
trainds = load_dataset('/tmp/data/taxi-train*', TRAIN_BATCH_SIZE, 'train')
# Evaluation dataset
evalds = load_dataset('/tmp/data/taxi-valid*', 1000, 'eval').take(NUM_EVAL_EXAMPLES//1000)
# Needs to be specified since the dataset is infinite
# This happens because the repeat method was used when creating the dataset
steps_per_epoch = NUM_TRAIN_EXAMPLES // TRAIN_BATCH_SIZE
# Train the model and save the history
history = model.fit(trainds,
validation_data=evalds,
epochs=NUM_EPOCHS,
steps_per_epoch=steps_per_epoch)
Epoch 1/20
1863/1863 [==============================] - 18s 4ms/step - loss: 103.4194 - rmse: 10.1695 - mse: 103.4194 - val_loss: 101.0493 - val_rmse: 10.0523 - val_mse: 101.0493
Epoch 2/20
1863/1863 [==============================] - 8s 4ms/step - loss: 101.7517 - rmse: 10.0872 - mse: 101.7517 - val_loss: 103.4912 - val_rmse: 10.1731 - val_mse: 103.4912
Epoch 3/20
1863/1863 [==============================] - 7s 4ms/step - loss: 103.7203 - rmse: 10.1843 - mse: 103.7203 - val_loss: 100.7266 - val_rmse: 10.0363 - val_mse: 100.7266
Epoch 4/20
1863/1863 [==============================] - 8s 4ms/step - loss: 101.4938 - rmse: 10.0744 - mse: 101.4938 - val_loss: 101.0047 - val_rmse: 10.0501 - val_mse: 101.0047
Epoch 5/20
1863/1863 [==============================] - 8s 4ms/step - loss: 102.7479 - rmse: 10.1365 - mse: 102.7479 - val_loss: 98.8334 - val_rmse: 9.9415 - val_mse: 98.8334
Epoch 6/20
1863/1863 [==============================] - 7s 4ms/step - loss: 100.6781 - rmse: 10.0338 - mse: 100.6781 - val_loss: 99.4240 - val_rmse: 9.9712 - val_mse: 99.4240
Epoch 7/20
1863/1863 [==============================] - 8s 4ms/step - loss: 104.7110 - rmse: 10.2328 - mse: 104.7110 - val_loss: 100.5087 - val_rmse: 10.0254 - val_mse: 100.5087
Epoch 8/20
1863/1863 [==============================] - 8s 4ms/step - loss: 101.1817 - rmse: 10.0589 - mse: 101.1817 - val_loss: 100.5816 - val_rmse: 10.0290 - val_mse: 100.5816
Epoch 9/20
1863/1863 [==============================] - 9s 5ms/step - loss: 104.6394 - rmse: 10.2293 - mse: 104.6394 - val_loss: 99.7949 - val_rmse: 9.9897 - val_mse: 99.7949
Epoch 10/20
1863/1863 [==============================] - 8s 4ms/step - loss: 102.1272 - rmse: 10.1058 - mse: 102.1272 - val_loss: 101.3765 - val_rmse: 10.0686 - val_mse: 101.3765
Epoch 11/20
1863/1863 [==============================] - 8s 4ms/step - loss: 101.6270 - rmse: 10.0810 - mse: 101.6270 - val_loss: 103.6213 - val_rmse: 10.1795 - val_mse: 103.6213
Epoch 12/20
1863/1863 [==============================] - 10s 5ms/step - loss: 101.9854 - rmse: 10.0988 - mse: 101.9854 - val_loss: 100.7637 - val_rmse: 10.0381 - val_mse: 100.7637
Epoch 13/20
1863/1863 [==============================] - 8s 4ms/step - loss: 103.0033 - rmse: 10.1491 - mse: 103.0033 - val_loss: 98.4518 - val_rmse: 9.9223 - val_mse: 98.4518
Epoch 14/20
1863/1863 [==============================] - 8s 4ms/step - loss: 103.7631 - rmse: 10.1864 - mse: 103.7631 - val_loss: 99.4594 - val_rmse: 9.9729 - val_mse: 99.4594
Epoch 15/20
1863/1863 [==============================] - 8s 4ms/step - loss: 99.7975 - rmse: 9.9899 - mse: 99.7975 - val_loss: 98.6264 - val_rmse: 9.9311 - val_mse: 98.6264
Epoch 16/20
1863/1863 [==============================] - 8s 4ms/step - loss: 100.9281 - rmse: 10.0463 - mse: 100.9281 - val_loss: 100.0372 - val_rmse: 10.0019 - val_mse: 100.0372
Epoch 17/20
1863/1863 [==============================] - 8s 4ms/step - loss: 103.0214 - rmse: 10.1499 - mse: 103.0214 - val_loss: 100.2084 - val_rmse: 10.0104 - val_mse: 100.2084
Epoch 18/20
1863/1863 [==============================] - 7s 4ms/step - loss: 101.4339 - rmse: 10.0714 - mse: 101.4339 - val_loss: 101.0658 - val_rmse: 10.0532 - val_mse: 101.0658
Epoch 19/20
1863/1863 [==============================] - 8s 4ms/step - loss: 102.7378 - rmse: 10.1360 - mse: 102.7378 - val_loss: 101.1634 - val_rmse: 10.0580 - val_mse: 101.1634
Epoch 20/20
1863/1863 [==============================] - 8s 4ms/step - loss: 103.1401 - rmse: 10.1558 - mse: 103.1401 - val_loss: 98.7793 - val_rmse: 9.9388 - val_mse: 98.7793
Visualize training curves
Now lets visualize the training history of the model with the raw features:
# Function for plotting metrics for a given history
def plot_curves(history, metrics):
nrows = 1
ncols = 2
fig = plt.figure(figsize=(10, 5))
for idx, key in enumerate(metrics):
ax = fig.add_subplot(nrows, ncols, idx+1)
plt.plot(history.history[key])
plt.plot(history.history[f'val_{key}'])
plt.title(f'model {key}')
plt.ylabel(key)
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
# Plot history metrics
plot_curves(history, ['loss', 'mse'])
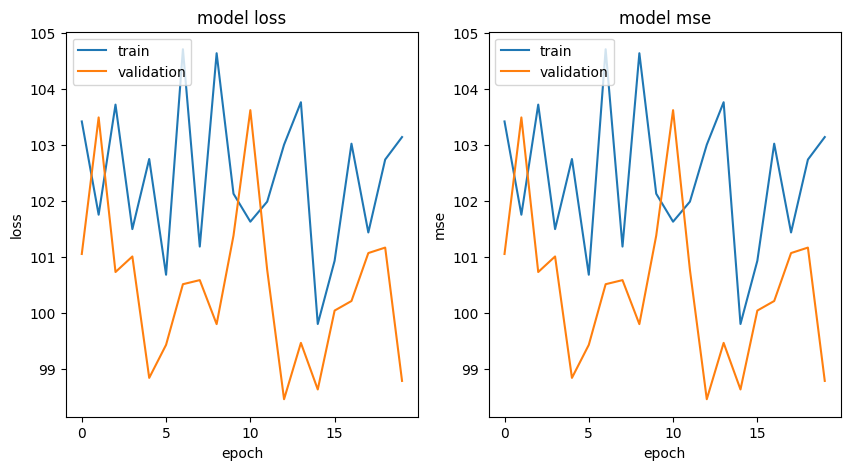
The training history doesn’t look very promising showing an erratic behaviour. Looks like the training process struggled to transverse the high dimensional space that the current features create.
Nevertheless let’s use it for prediction.
Notice that the latitude and longitude values should revolve around (37, 45) and (-70, -78) respectively since these are the range of coordinates for New York city.
# Define a taxi ride (a data point)
taxi_ride = {
'pickup_longitude': tf.convert_to_tensor([-73.982683]),
'pickup_latitude': tf.convert_to_tensor([40.742104]),
'dropoff_longitude': tf.convert_to_tensor([-73.983766]),
'dropoff_latitude': tf.convert_to_tensor([40.755174]),
'passenger_count': tf.convert_to_tensor([3.0]),
'hourofday': tf.convert_to_tensor([3.0]),
'dayofweek': tf.convert_to_tensor([3.0]),
}
# Use the model to predict
prediction = model.predict(taxi_ride, steps=1)
# Print prediction
print(f"the model predicted a fare total of {float(prediction):.2f} USD for the ride.")
1/1 [==============================] - 0s 140ms/step
the model predicted a fare total of 11.98 USD for the ride.
The model predicted this particular ride to be around 12 USD. However you know the model performance is not the best as it was showcased by the training history. Let’s improve it by using Feature Engineering.
Improve Model Performance Using Feature Engineering
Going forward you will only use geo-spatial features as these are the most relevant when calculating the fare since this value is mostly dependant on the distance transversed:
# Drop dayofweek and hourofday features
NUMERIC_COLS = ['pickup_longitude', 'pickup_latitude',
'dropoff_longitude', 'dropoff_latitude']
Since you are dealing exclusively with geospatial data you will create some transformations that are aware of this geospatial nature. This help the model make a better representation of the problem at hand.
For instance the model cannot magically understand what a coordinate is supposed to represent and since the data is taken from New York only, the latitude and longitude revolve around (37, 45) and (-70, -78) respectively, which is arbitrary for the model. A good first step is to scale these values.
Notice all transformations are created by defining functions.
def scale_longitude(lon_column):
return (lon_column + 78)/8.
def scale_latitude(lat_column):
return (lat_column - 37)/8.
Another important fact is that the fare of a taxi ride is proportional to the distance of the ride. But as the features currently are, there is no way for the model to infer that the pair of (pickup_latitude, pickup_longitude) represent the point where the passenger started the ride and the pair (dropoff_latitude, dropoff_longitude) represent the point where the ride ended. More importantly, the model is not aware that the distance between these two points is crucial for predicting the fare.
To solve this, a new feature (which is a transformation of the other ones) that provides this information is required.
def euclidean(params):
lon1, lat1, lon2, lat2 = params
londiff = lon2 - lon1
latdiff = lat2 - lat1
return tf.sqrt(londiff*londiff + latdiff*latdiff)
Applying transformations
Now you will define the transform function which will apply the previously defined transformation functions. To apply the actual transformations you will be using Lambda layers apply a function to values (in this case the inputs).
def transform(inputs, numeric_cols):
# Make a copy of the inputs to apply the transformations to
transformed = inputs.copy()
# Define feature columns
feature_columns = {
colname: tf.feature_column.numeric_column(colname)
for colname in numeric_cols
}
# Scaling longitude from range [-70, -78] to [0, 1]
for lon_col in ['pickup_longitude', 'dropoff_longitude']:
transformed[lon_col] = layers.Lambda(
scale_longitude,
name=f"scale_{lon_col}")(inputs[lon_col])
# Scaling latitude from range [37, 45] to [0, 1]
for lat_col in ['pickup_latitude', 'dropoff_latitude']:
transformed[lat_col] = layers.Lambda(
scale_latitude,
name=f'scale_{lat_col}')(inputs[lat_col])
# add Euclidean distance
transformed['euclidean'] = layers.Lambda(
euclidean,
name='euclidean')([inputs['pickup_longitude'],
inputs['pickup_latitude'],
inputs['dropoff_longitude'],
inputs['dropoff_latitude']])
# Add euclidean distance to feature columns
feature_columns['euclidean'] = fc.numeric_column('euclidean')
return transformed, feature_columns
Update the model
Next, you’ll create the DNN model now with the engineered (transformed) features.
def build_dnn_model():
# input layer (notice type of float32 since features are numeric)
inputs = {
colname: layers.Input(name=colname, shape=(), dtype='float32')
for colname in NUMERIC_COLS
}
# transformed features
transformed, feature_columns = transform(inputs, numeric_cols=NUMERIC_COLS)
# Constructor for DenseFeatures takes a list of numeric columns
# and the resulting tensor takes a dictionary of Lambda layers
dnn_inputs = layers.DenseFeatures(feature_columns.values())(transformed)
# two hidden layers of 32 and 8 units, respectively
h1 = layers.Dense(32, activation='relu', name='h1')(dnn_inputs)
h2 = layers.Dense(8, activation='relu', name='h2')(h1)
# final output is a linear activation because this is a regression problem
output = layers.Dense(1, activation='linear', name='fare')(h2)
# Create model with inputs and output
model = models.Model(inputs, output)
# Compile model (Mean Squared Error is suitable for regression)
model.compile(optimizer='adam',
loss='mse',
metrics=[tf.keras.metrics.RootMeanSquaredError(name='rmse'), 'mse'])
return model
# Save compiled model into a variable
model = build_dnn_model()
Let’s see how the model architecture has changed.
# Plot the layer architecture and relationship between input features
tf.keras.utils.plot_model(model, 'dnn_model_engineered.png', show_shapes=False, rankdir='LR')
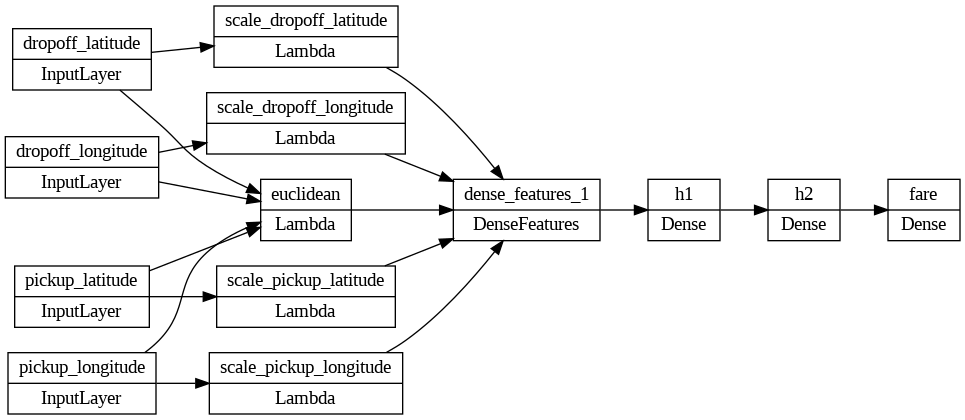
This plot is very useful for understanding the relationships and dependencies between the original and the transformed features!
Notice that the input of the model now consists of 5 features instead of the original 7, thus reducing the dimensionality of the problem.
Let’s now train the model that includes feature engineering.
# Train the model and save the history
history = model.fit(trainds,
validation_data=evalds,
epochs=NUM_EPOCHS,
steps_per_epoch=steps_per_epoch)
Epoch 1/20
/usr/local/lib/python3.10/dist-packages/keras/engine/functional.py:639: UserWarning: Input dict contained keys ['passenger_count', 'hourofday', 'dayofweek'] which did not match any model input. They will be ignored by the model.
inputs = self._flatten_to_reference_inputs(inputs)
1863/1863 [==============================] - 12s 5ms/step - loss: 110.6458 - rmse: 10.5188 - mse: 110.6458 - val_loss: 83.3635 - val_rmse: 9.1304 - val_mse: 83.3635
Epoch 2/20
1863/1863 [==============================] - 8s 5ms/step - loss: 65.3295 - rmse: 8.0827 - mse: 65.3295 - val_loss: 35.1750 - val_rmse: 5.9309 - val_mse: 35.1750
Epoch 3/20
1863/1863 [==============================] - 8s 4ms/step - loss: 29.3671 - rmse: 5.4191 - mse: 29.3671 - val_loss: 30.0049 - val_rmse: 5.4777 - val_mse: 30.0049
Epoch 4/20
1863/1863 [==============================] - 7s 4ms/step - loss: 30.1486 - rmse: 5.4908 - mse: 30.1486 - val_loss: 28.4762 - val_rmse: 5.3363 - val_mse: 28.4762
Epoch 5/20
1863/1863 [==============================] - 8s 4ms/step - loss: 28.2970 - rmse: 5.3195 - mse: 28.2970 - val_loss: 28.0630 - val_rmse: 5.2975 - val_mse: 28.0630
Epoch 6/20
1863/1863 [==============================] - 7s 4ms/step - loss: 27.9992 - rmse: 5.2914 - mse: 27.9992 - val_loss: 26.3136 - val_rmse: 5.1297 - val_mse: 26.3136
Epoch 7/20
1863/1863 [==============================] - 8s 4ms/step - loss: 25.2383 - rmse: 5.0238 - mse: 25.2383 - val_loss: 25.7710 - val_rmse: 5.0765 - val_mse: 25.7710
Epoch 8/20
1863/1863 [==============================] - 8s 4ms/step - loss: 26.8133 - rmse: 5.1782 - mse: 26.8133 - val_loss: 25.9439 - val_rmse: 5.0935 - val_mse: 25.9439
Epoch 9/20
1863/1863 [==============================] - 8s 4ms/step - loss: 25.6859 - rmse: 5.0681 - mse: 25.6859 - val_loss: 26.2134 - val_rmse: 5.1199 - val_mse: 26.2134
Epoch 10/20
1863/1863 [==============================] - 8s 4ms/step - loss: 24.4314 - rmse: 4.9428 - mse: 24.4314 - val_loss: 26.0488 - val_rmse: 5.1038 - val_mse: 26.0488
Epoch 11/20
1863/1863 [==============================] - 8s 4ms/step - loss: 24.2909 - rmse: 4.9286 - mse: 24.2909 - val_loss: 25.6966 - val_rmse: 5.0692 - val_mse: 25.6966
Epoch 12/20
1863/1863 [==============================] - 7s 4ms/step - loss: 26.0885 - rmse: 5.1077 - mse: 26.0885 - val_loss: 25.9909 - val_rmse: 5.0981 - val_mse: 25.9909
Epoch 13/20
1863/1863 [==============================] - 8s 4ms/step - loss: 24.7382 - rmse: 4.9737 - mse: 24.7382 - val_loss: 25.6459 - val_rmse: 5.0642 - val_mse: 25.6459
Epoch 14/20
1863/1863 [==============================] - 7s 4ms/step - loss: 26.0051 - rmse: 5.0995 - mse: 26.0051 - val_loss: 25.9119 - val_rmse: 5.0904 - val_mse: 25.9119
Epoch 15/20
1863/1863 [==============================] - 8s 4ms/step - loss: 24.6045 - rmse: 4.9603 - mse: 24.6045 - val_loss: 25.7608 - val_rmse: 5.0755 - val_mse: 25.7608
Epoch 16/20
1863/1863 [==============================] - 8s 4ms/step - loss: 24.3606 - rmse: 4.9356 - mse: 24.3606 - val_loss: 26.0090 - val_rmse: 5.0999 - val_mse: 26.0090
Epoch 17/20
1863/1863 [==============================] - 7s 4ms/step - loss: 26.2743 - rmse: 5.1258 - mse: 26.2743 - val_loss: 25.8622 - val_rmse: 5.0855 - val_mse: 25.8622
Epoch 18/20
1863/1863 [==============================] - 8s 4ms/step - loss: 24.1549 - rmse: 4.9148 - mse: 24.1549 - val_loss: 25.3940 - val_rmse: 5.0392 - val_mse: 25.3940
Epoch 19/20
1863/1863 [==============================] - 8s 4ms/step - loss: 22.2844 - rmse: 4.7206 - mse: 22.2844 - val_loss: 24.8175 - val_rmse: 4.9817 - val_mse: 24.8175
Epoch 20/20
1863/1863 [==============================] - 7s 4ms/step - loss: 27.4879 - rmse: 5.2429 - mse: 27.4879 - val_loss: 25.7859 - val_rmse: 5.0780 - val_mse: 25.7859
Notice that the features passenger_count, hourofday and dayofweek were excluded since they were omitted when defining the input pipeline.
Now lets visualize the training history of the model with the engineered features.
# Plot history metrics
plot_curves(history, ['loss', 'mse'])
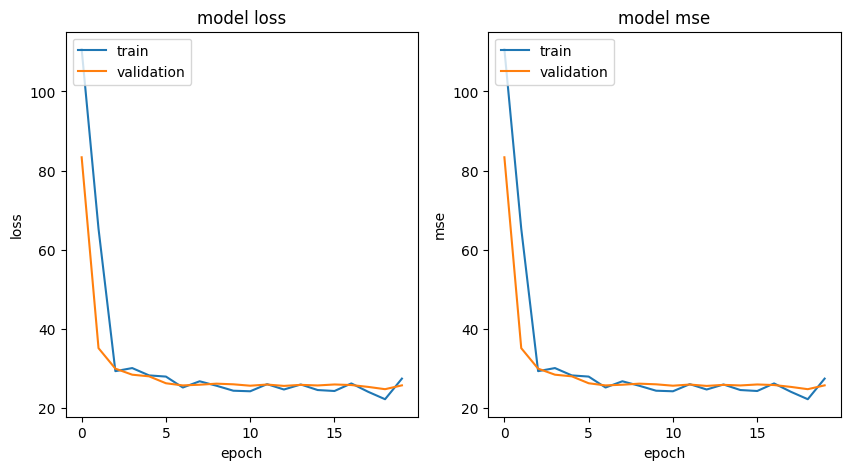
This looks a lot better than the previous training history! Now the loss and error metrics are decreasing with each epoch and both curves (train and validation) are very close to each other. Nice job!
Let’s do a prediction with this new model on the example we previously used.
# Use the model to predict
prediction = model.predict(taxi_ride, steps=1)
# Print prediction
print(f"the model predicted a fare total of {float(prediction):.2f} USD for the ride.")
1/1 [==============================] - 0s 113ms/step
the model predicted a fare total of 6.73 USD for the ride.
Wow, now the model predicts a fare that is roughly half of what the previous model predicted! Looks like the model with the raw features was overestimating the fare by a great margin.
Notice that you get a warning since the taxi_ride dictionary contains information about the unused features. You can supress it by redefining taxi_ride without these values but it is useful to know that Keras is smart enough to handle it on its own.
Congratulations on finishing this ungraded lab! Now you should have a clearer understanding of the importance and impact of performing feature engineering on your data.
This process is very domain-specific and requires a great understanding of the situation that is being modelled. Because of this, new techniques that switch from a manual to an automatic feature engineering have been developed and you will check some of them in an upcoming lab.
Keep it up!